

 Время чтения - 5 минут
Время чтения - 5 минут


Технология оптического распознавания символов (OCR) позволяет считывать текст с картинок, сканов и фотографий. Благодаря ей любые книги и документы становятся редактируемыми, а фрагменты материалов можно легко копировать. Программа PDF Commander распознает текст с точностью до 99%, поддерживает 100+ языков и умеет работать с двумя языками одновременно.
Расскажем, как выполнить быстрое и интеллектуальное распознавание и как правильно настроить определение сегментов.
Быстрое распознавание
Этот модуль подходит для печатных сканов хорошего качества.
- 1. Нажмите по кнопке «Выбрать файл» и загрузите PDF-документ или изображение.
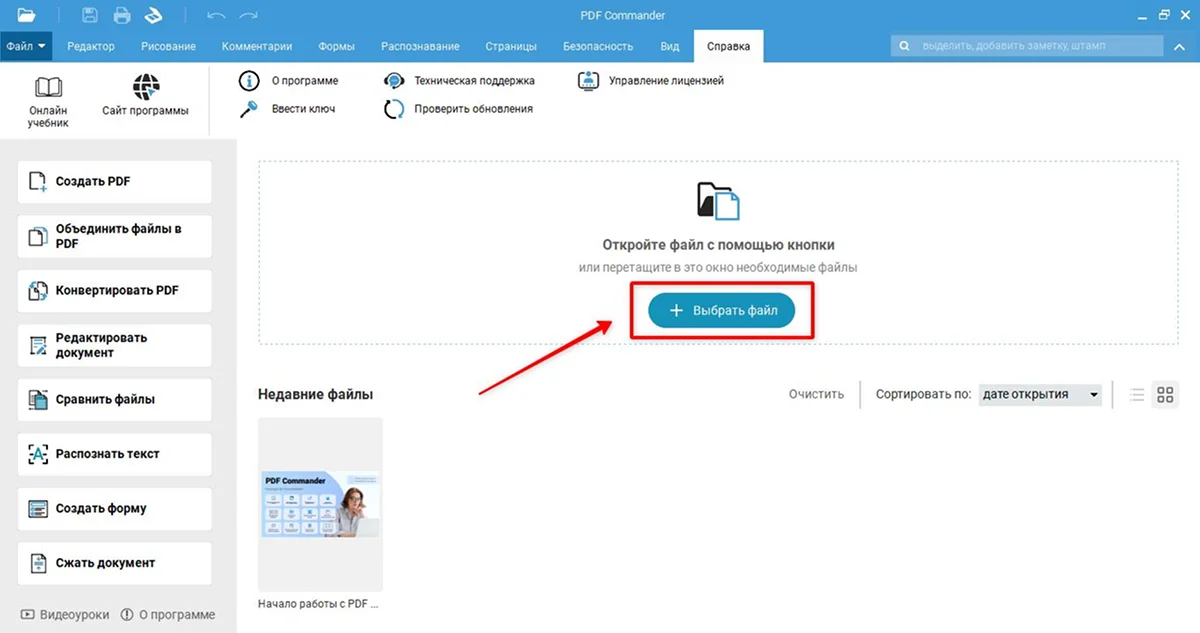
- 2. Перейдите в раздел «Распознавание» и щелкните «Распознать текст».
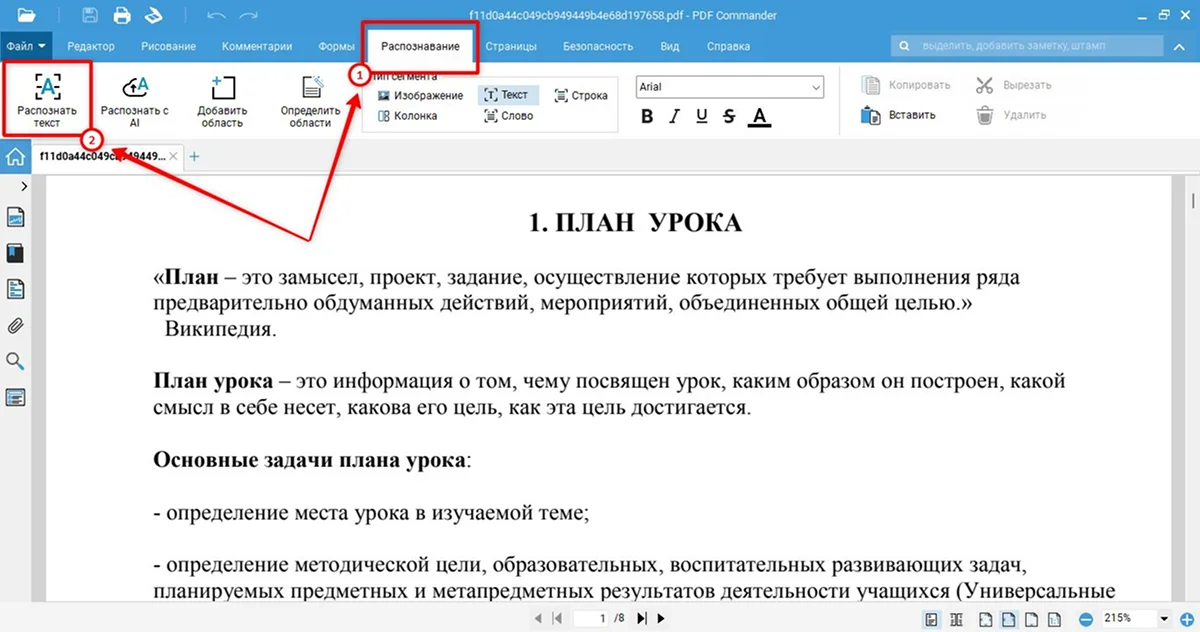
- 3. В открывшемся окне выберите режим «Текущая страница», чтобы работать только с ней, или отметьте все листы. Также вы можете задать диапазон. В модуле укажите тип «Быстрый».
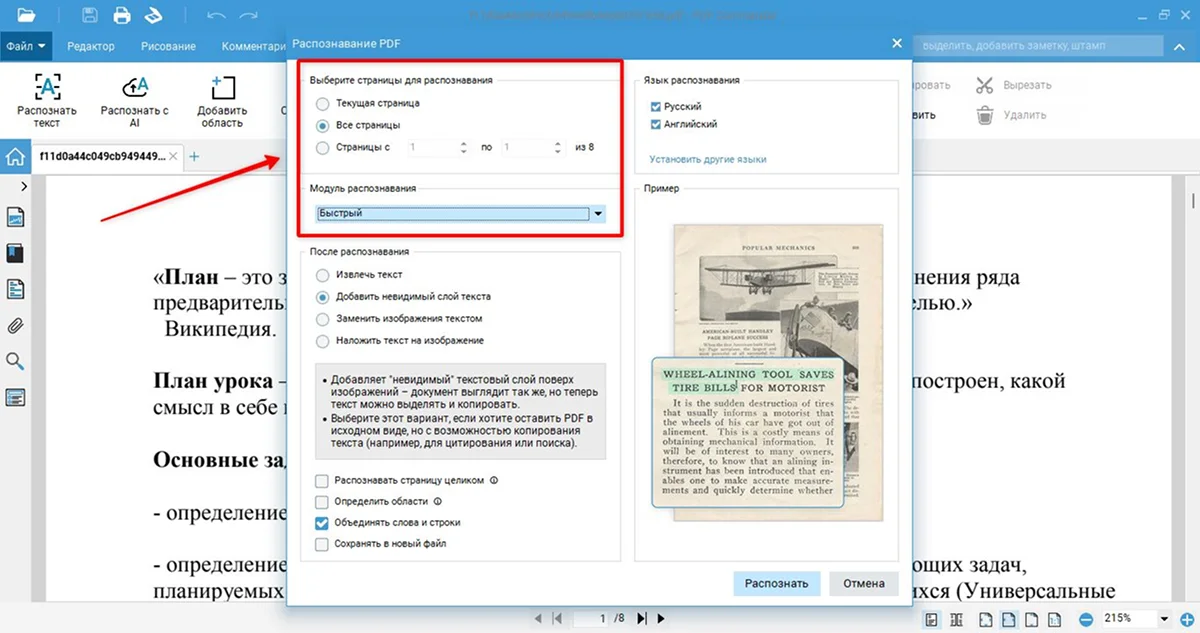
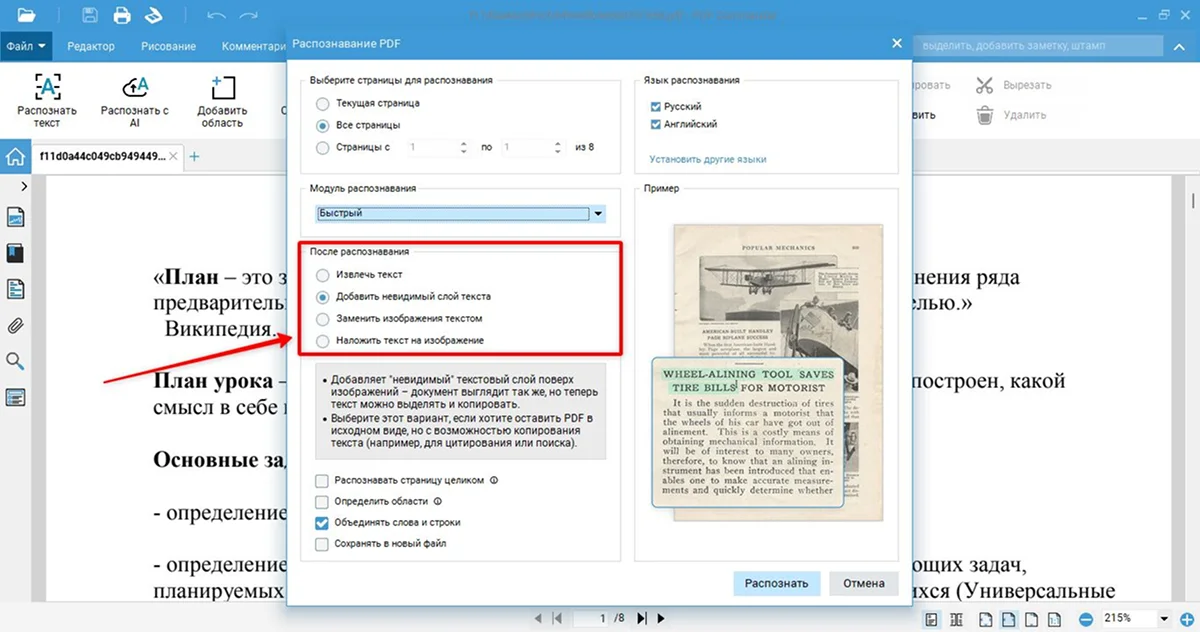
- 4. Выделите строку «Извлечь текст». Отметьте галочкой пункт «Сохранять в новый файл», чтобы вынести содержимое в текстовый документ. Если выбрать «Добавить невидимый слой текста», в исходном файле будет работать поиск по словам и копирование.
- 5. Определите язык распознавания. По умолчанию в программе доступен только русский и английский. Чтобы загрузить все возможные варианты, кликните «Установить другие языки» в окне «Язык распознавания».
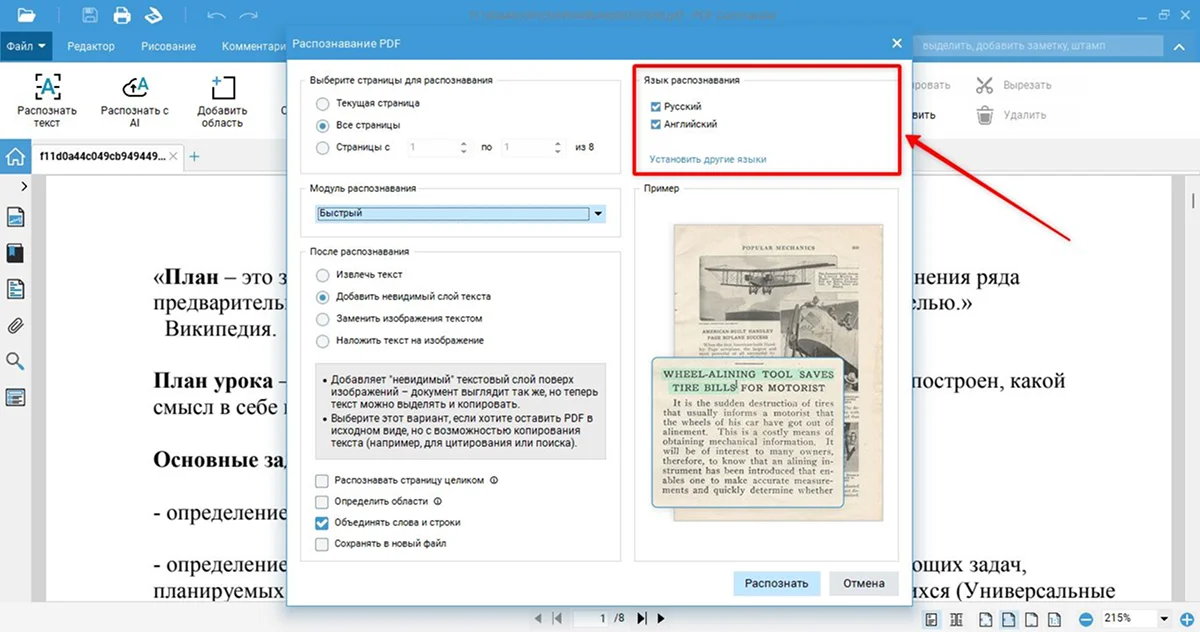
- 6. Запустите процесс, кликнув по кнопке «Распознать».
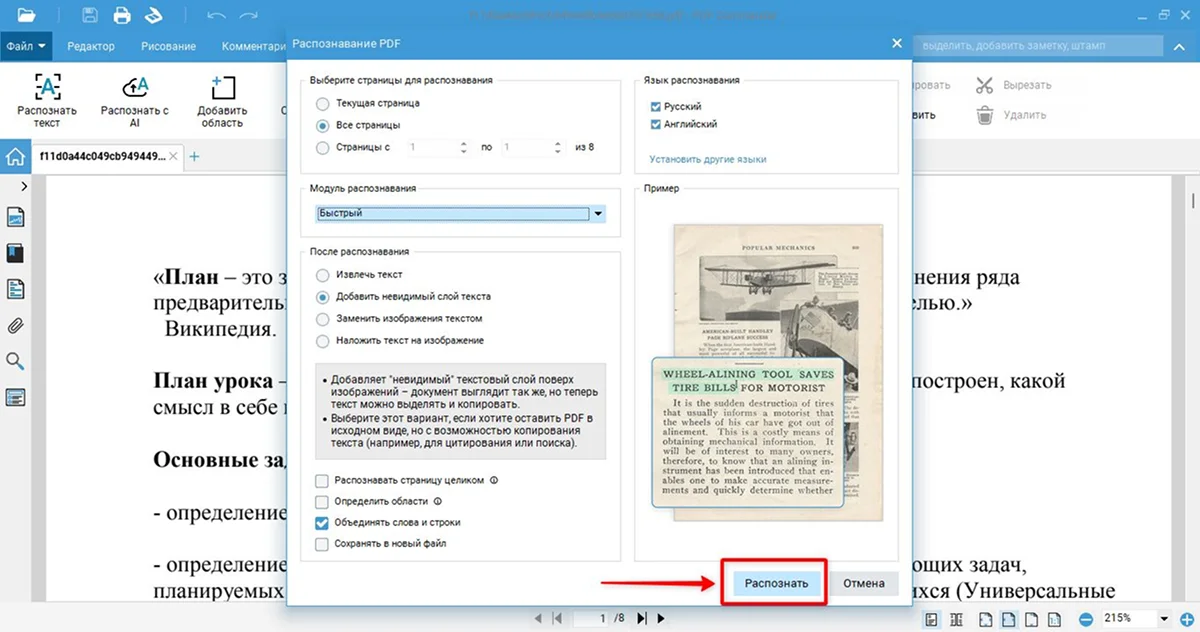
- 7. Сохраните результат.
ИИ-распознавание
Используйте интеллектуальный модуль, чтобы работать с испорченными сканами, ручными заметками и двуязычными текстами.
- 1. Загрузите документ и во вкладке «Распознавание» выберите опцию «Распознать AI».
- 2. Определите языки самостоятельно или выберите «Автоопределение». Система распознает текст на 40+ языках.
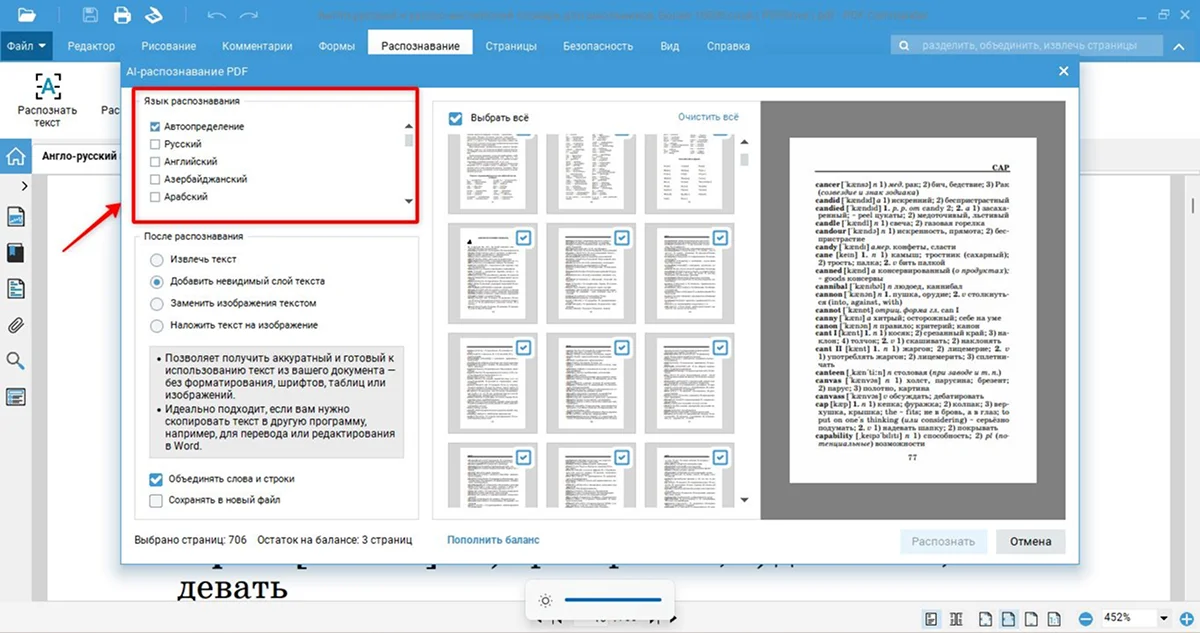
- 3. Поставьте галочки у пунктов «Извлечь текст», «Сохранять в новый файл» и у нужных страниц. Чтобы выделить все листы, отметьте «Выбрать все».
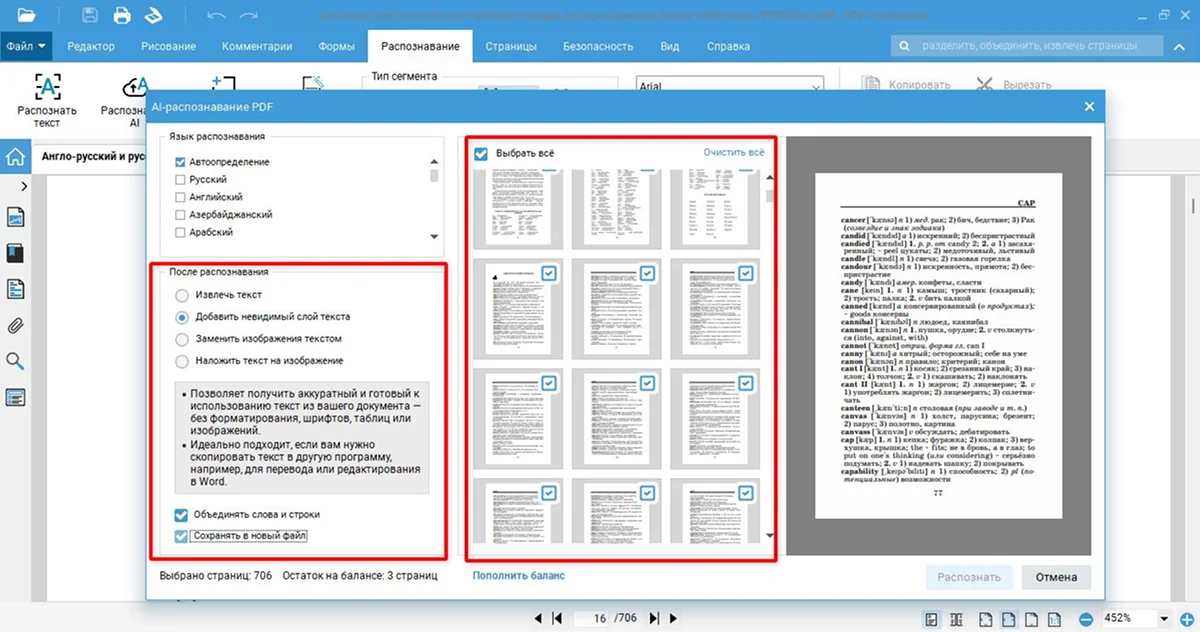
- 4. Кликните «Распознать».
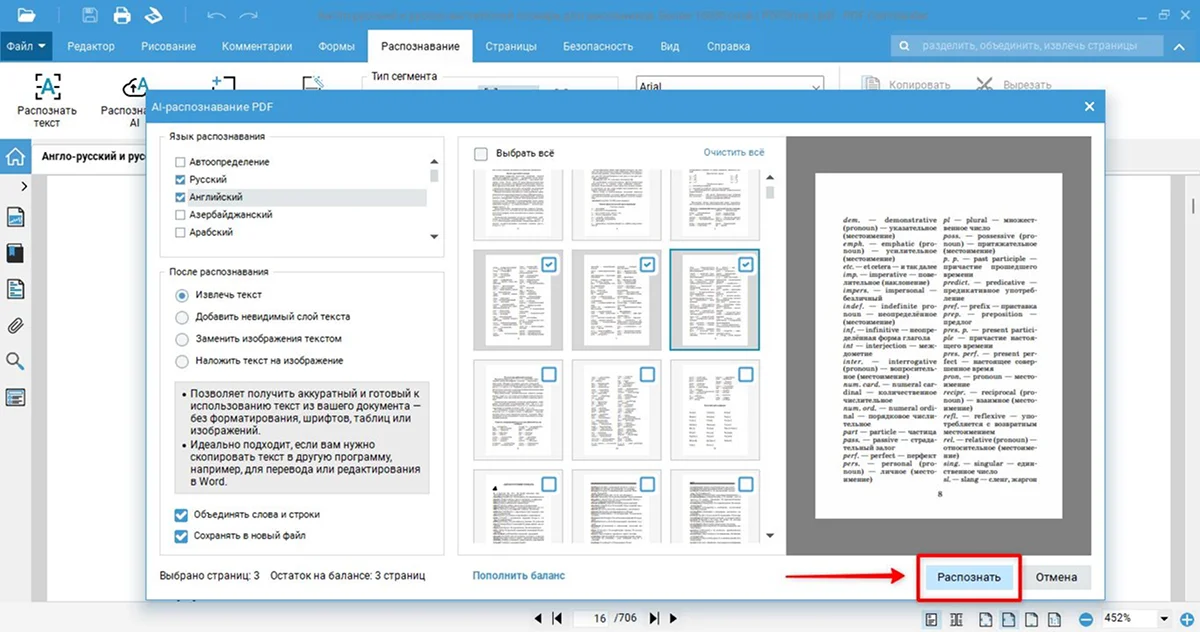
- 5. Определите место для сохранения нового документа и экспортируйте его.
Настройка сегментов
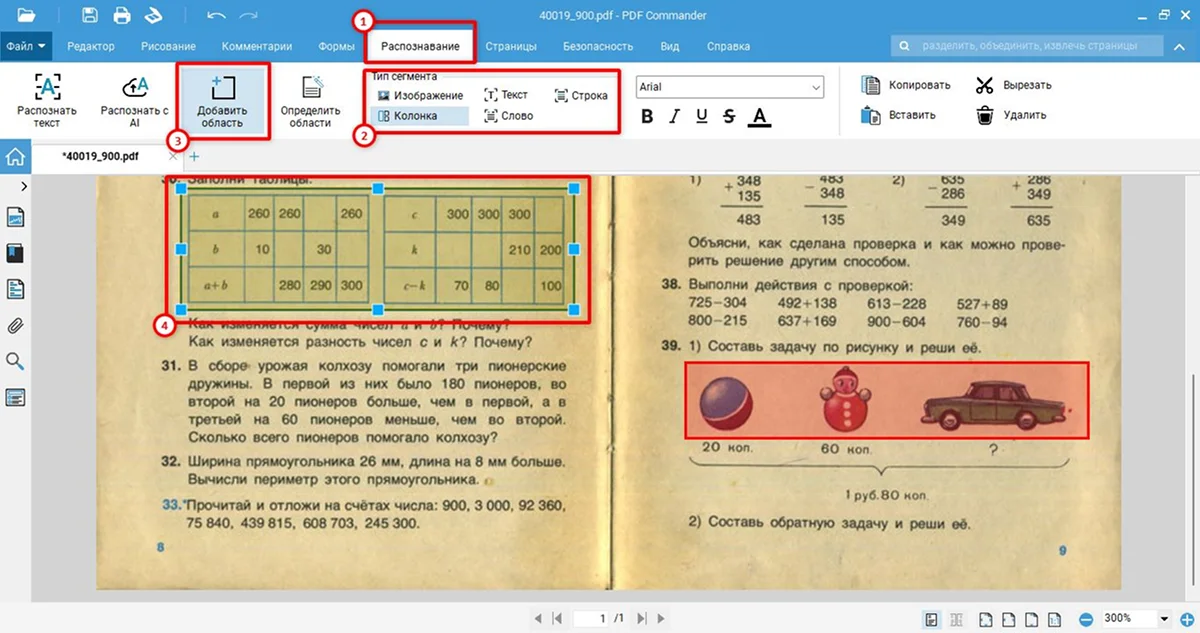
Чтобы система максимально точно распознала все символы и итоговый документ не потерял структуру, перед распознаванием вручную выделите нужные области — сегменты. В PDF Commander доступно пять типов, выберите тот, который подходит для вашего текста:
- Изображение — исключает картинку из распознавания. Используйте, чтобы программа не пыталась прочитать рисунки или логотипы.
- Колонка — для таблиц или узких столбцов текста. Помогает, когда строки ошибочно сливаются в сплошной массив.
- Текст — подходит для обычных структурированных документов, например, статей, отчетов и книг. Программа сама определяет абзацы, таблицы и заголовки.
- Слово — для разрозненного текста: отдельные подписи, короткие фразы, выноски. Обрабатывает каждое слово по отдельности.
- Строки — подходит для списков, заголовков или фрагментов, где важна каждая строка. Распознает текст построчно.
Как добавить сегмент:
- 1. Импортируйте скан в программу.
- 2. Перейдите в раздел «Распознавание», выберите нужный тип сегмента, нажмите «Добавить область» и выделите фрагмент на странице.
- 3. Повторите шаги для всех необходимых зон — и запускайте распознавание.
После распознавания вы можете искать слова по документу, копировать любые фрагменты. Кроме того, в PDF Commander доступны и другие возможности: создавать документы с нуля, редактировать готовые файлы, ставить штампы и накладывать цифровые подписи. Попробуйте эти и другие функции прямо сейчас!