
 Время чтения - 10 минут
Время чтения - 10 минут




Как эксперты PDF Commander проверяют софт для обзора?
- Изучают тарифы и политику разработчиков
- Тестируют программы на разных ПК
- Исследуют отзывы реальных пользователей
- Проверяют доступность и качество поддержки
- Исключают софт, который не обновляется

Технология OCR (optical character recognition) выполняет оптическое распознавание символов. Если ее применить, книги и документация переведутся в удобный редактируемый вид, а материалы можно будет скопировать. Это значительно упрощает работу образовательных учреждений и многих других сфер.
В статье расскажу, как подготовить документы для OCR, а также поэтапно разберем, как распознать текст в ПДФ в программе на ПК.
Какие образцы для распознавания выбраны и почему
Когда я начала готовить материал для этой статьи, мне было важно подобрать подходящие примеры PDF-документов. Поэтому я остановилась на трех типах, каждый из которых представляет определенную сложность:
- Фото договора — без графики, но в виде изображения. Такие бумаги часто приходят по электронной почте или из архивов. От них требуется максимальная точность, особенно в отношении цифр и юридических формулировок.
- Учебник с картинками — это смешанный контент, в котором надписи на странице переплетаются с иллюстрациями, схемами и таблицами. Здесь важно, чтобы программа сохраняла логическую структуру страницы.
- Документ на двух языках, английском и русском — проверка на мультиязычность. Многие системы оптического распознавания символов по умолчанию настроены на один язык. При одновременном использовании кириллицы и латиницы OCR может допускать ошибки или игнорировать один из языков.
Эти три примера охватывают большинство повседневных ситуаций. Они позволяют проверить точность работы: в реальной жизни редко встречается идеальный чистый текст без иллюстраций, таблиц или иноязычных вставок.
Как понять, что мой документ готов к распознаванию
Вот основные моменты, на которые я всегда обращаю внимание:
- Формат. Иногда скачанные из сети сканы сохраняются в WEBP. Такой формат не подходит для прямой работы c помощью технологии OCR: сначала нужно перевести отсканированные документы в ПДФ. Не нуждаются в считывании TXT и Microsoft Word: здесь вы сразу можете выделить и скопировать надписи.
- Отсутствие пароля. В защищенном PDF-файле программное обеспечение не сможет считать текст с ПДФ. Проверьте, открывается ли документ без запроса пароля.
 Помните: снять защиту разрешено только, если вы являетесь владельцем ПДФ-документа или имеете на это разрешение. В противном случае ваши действия станут нарушением авторских прав и законодательства.
Помните: снять защиту разрешено только, если вы являетесь владельцем ПДФ-документа или имеете на это разрешение. В противном случае ваши действия станут нарушением авторских прав и законодательства.
- Качество сканирования. На фото не должно быть серьезных дефектов: пятен, складок, перекосов, засветов и т. п. Перед распознаванием текста с помощью OCR желательно улучшить качество изображения: выровнять страницу, закрыть тени по краям. Если есть возможность, просто отсканируйте заново.
- Шрифты. Рукописи или декоративные начертания, например имитацию почерка, можно определить только с AI-распознаванием. Эта операция занимает несколько минут. Если хотите быстро преобразовать отсканированные листы, убедитесь, что используются варианты классического шрифта, например, Times New Roman или Arial.
С материалом закончили. Следующий шаг — выбор ПО. Отдавайте предпочтение надежным редакторам, например PDF Commander. Такой софт обеспечивает высокую точность считывания и сохраняет структуру страницы. Далее покажу, как делать распознавание в этой программе.
Как выполнить распознавание официального документа
Технология OCR полезна как для работы, так и для учебы. С ней копирование информации займет 2-3 минуты — не придется перепечатывать страницы вручную.
Фотография документа
Если доступа к сканеру нет, то стоит воспользоваться телефоном или фотоаппаратом. Сделайте снимок или найдите изображение в памяти устройства. Также можно скачать его из вложений диалога в мессенджере или сделать скриншот экрана с фрагментом. Для успешного определения всех слов очень важно, чтобы исходное изображение было четким и ярким.
Инструкция, как распознать текст с картинки в PDF:
- 1. Нажмите «Открыть PDF» на стартовой странице. Выберите изображение в любом формате: PNG, JPG, GIF и другие.
- 2. Во вкладке «Распознавание» кликните «Распознать текст».
- 3. Нажмите «Текущая страница» или выберите все листы. В окне ниже задайте режим OCR: я использую быстрый модуль, т. к. взяла фото в хорошем качестве. Еще доступен интеллектуальный режим, он предназначен для испорченных сканов с низким контрастом, скотчем или ручными надписями.
Выделите пункт «Извлечь текст» и поставьте галочку «Сохранять в новый файл», определите язык распознавания. Подтвердите свои действия, щелкнув на кнопку «Распознать».
- 4. После обработки выберите место сохранения документа.
Вы можете добавить невидимый слой прямо в исходном документе. Тогда в нем будет работать быстрый поиск по словам и копирование.

Как правильно и легально распознать текст учебника
Как педагог, я часто сталкиваюсь с ситуациями, когда необходимо извлекать текста из пособия, чтобы подготовить карточки для занятий или включить цитату в методичку. Однако учебники являются объектами авторского права, и работать с ними нужно особенно внимательно.
Книги можно сканировать и распознавать с помощью OCR в учебных целях, например для занятий. Однако размещать такие копии в интернете, в том числе в социальных сетях, мессенджерах или на образовательных платформах, запрещено. Также вы можете цитировать произведение, однако есть условия: объем должен быть оправдан целью использования, нужно указать автора и источник (ст. 1274 ГК РФ).
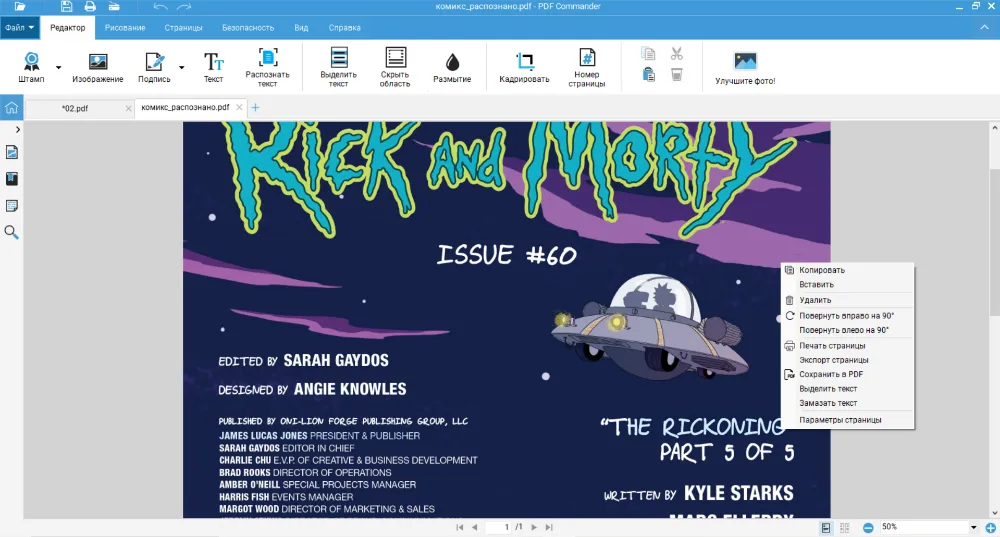
Инструкция по распознаванию PDF-текста в учебнике:
- 1. Загрузите файл в программу.
- 2. Выберите распознавание.
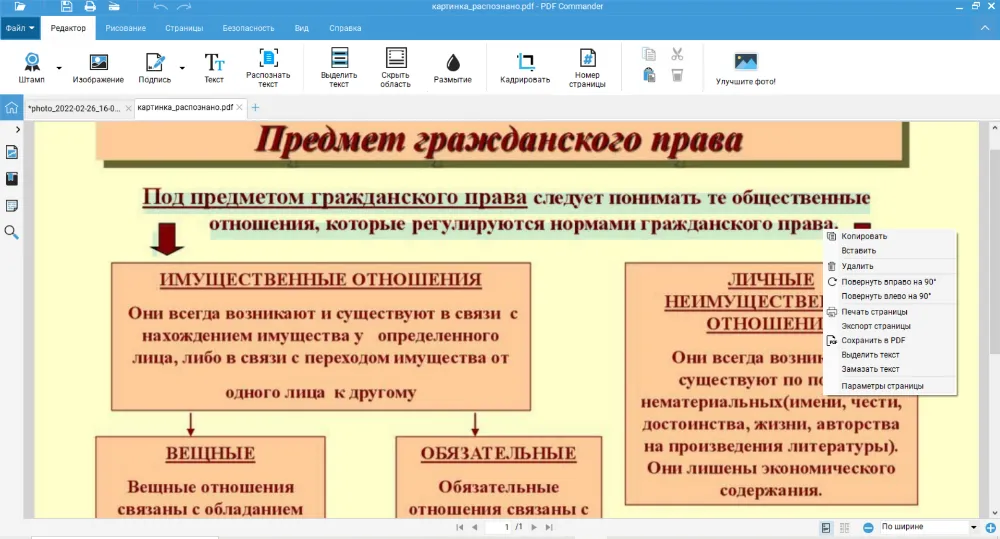
- 3. Задайте настройки для извлечения текста. Вы можете выбрать текущую страницу или определить диапазон. Задайте быстрый модуль. Также щелкните «Добавить невидимый слой текста» и поставьте галочку у нужного языка. После кликните «Распознать».
Нумерация учебника может не совпадать с реальным положением листов в документе. Прописывайте интервал всегда по вашей шкале, которая находится в нижней части экрана.
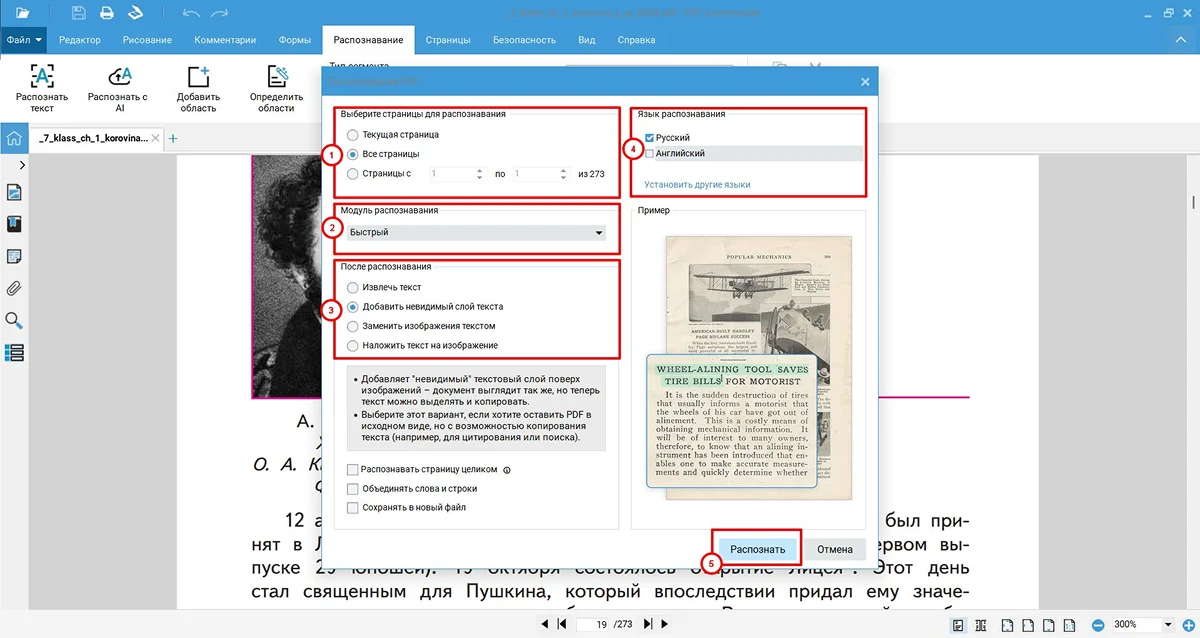
- 4. Система превратит отсканированные документы в редактируемые файлы. Скопируйте нужные данные в открывшемся окне или сохраните фрагмент.
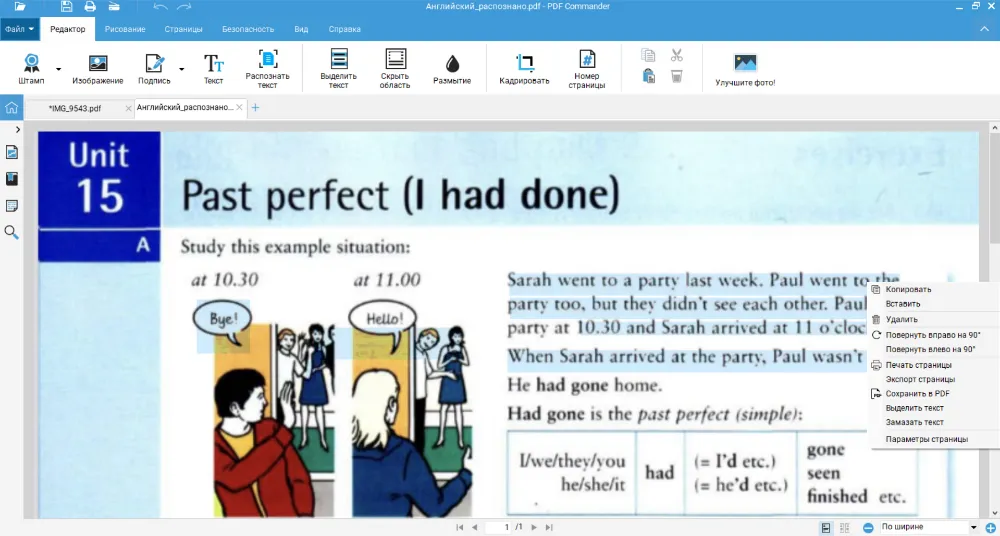
Как перевести в электронный вид текст файла на двух языках
В работе часто встречаются материалы, в которых используются два языка, например русский и английский. Это могут быть учебники с двуязычными пояснениями, выдержки из иностранных источников с переводом и прочее. Перед технологией OCR возникает особая задача: сохранить оба языка без искажений и не допустить, чтобы программа потеряла один из них.
Вот как сделать распознавание текста в ПДФ-файле:
- 1. Добавьте скан в систему, нажав «Открыть PDF».
- 2. Щелкните на распознавание в соответствующей вкладке.
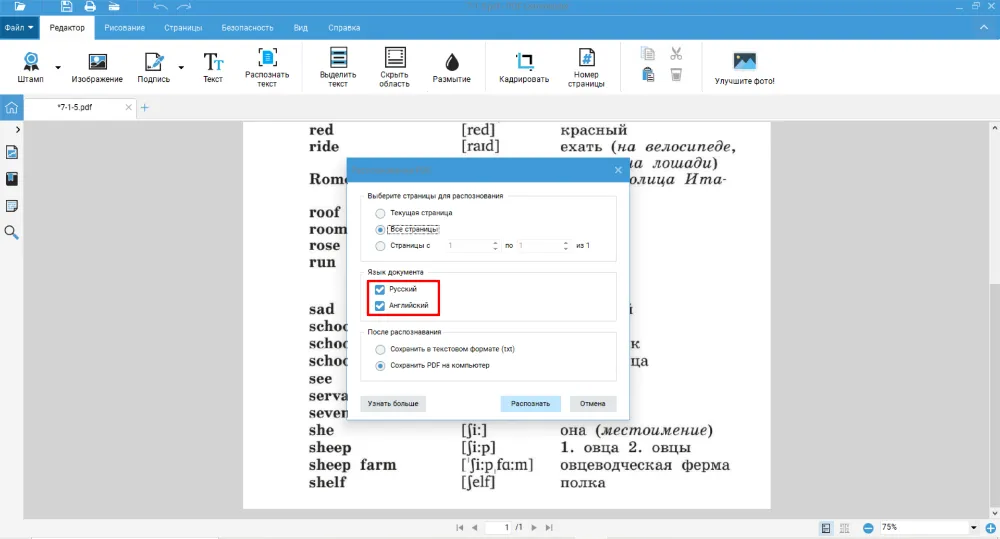
- 3. В открывшемся окне выберите количество листов и быстрый режим, добавьте невидимый слой и нажмите «Сохранить в новый файл». Важно: поставьте галочки у двух языков, например русского и английского. Далее нажмите на кнопку «Распознать».
 По умолчанию в софте установлены только два языка: русский и английский. Если вам понадобился другой, в настройках можно добавить французский, испанский, немецкий и еще 100+ вариантов.
По умолчанию в софте установлены только два языка: русский и английский. Если вам понадобился другой, в настройках можно добавить французский, испанский, немецкий и еще 100+ вариантов.
- 4. После завершения обработки определите папку для экспорта ПДФ-файла.
Что делать, если скан сильно поврежден
За все время работы с PDF Commander у меня не было случая, чтобы система отказалась определять символы — AI-считывание справляется даже с неудачными сканами.
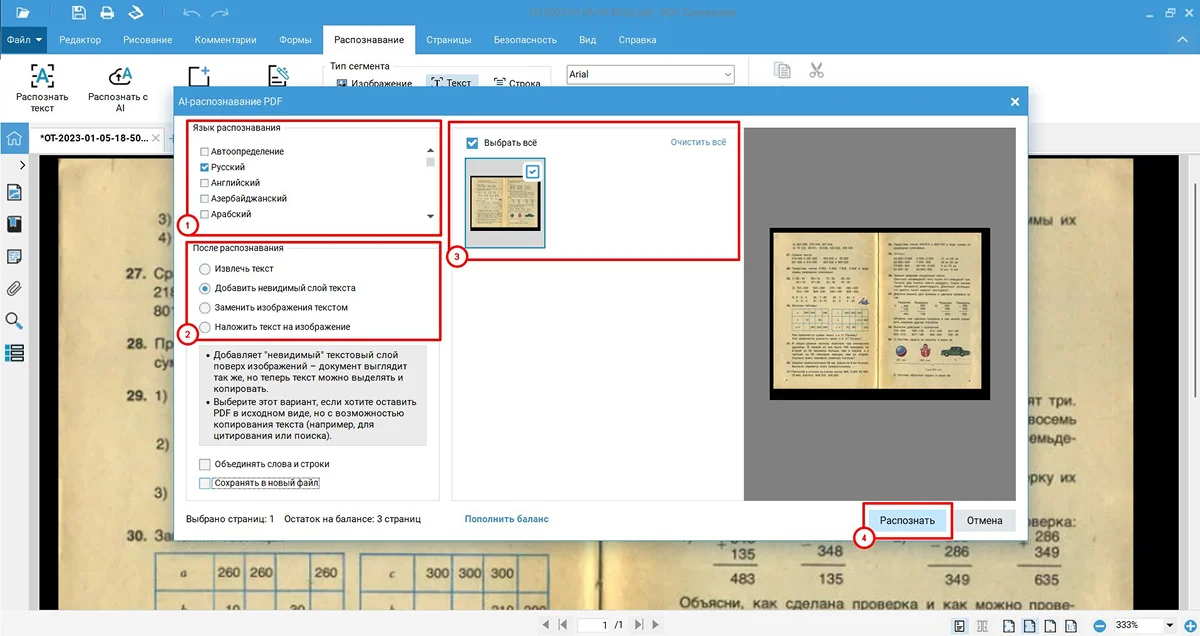
Как распознать текст в PDF на поврежденном изображении с помощью инструмента OCR:
- 1. Добавьте скан в программу с помощью кнопки «Открыть PDF».
- 2. Перейдите в режим определения надписей с ИИ, нажав кнопку «AI-распознавание»
сверху на панели инструментов.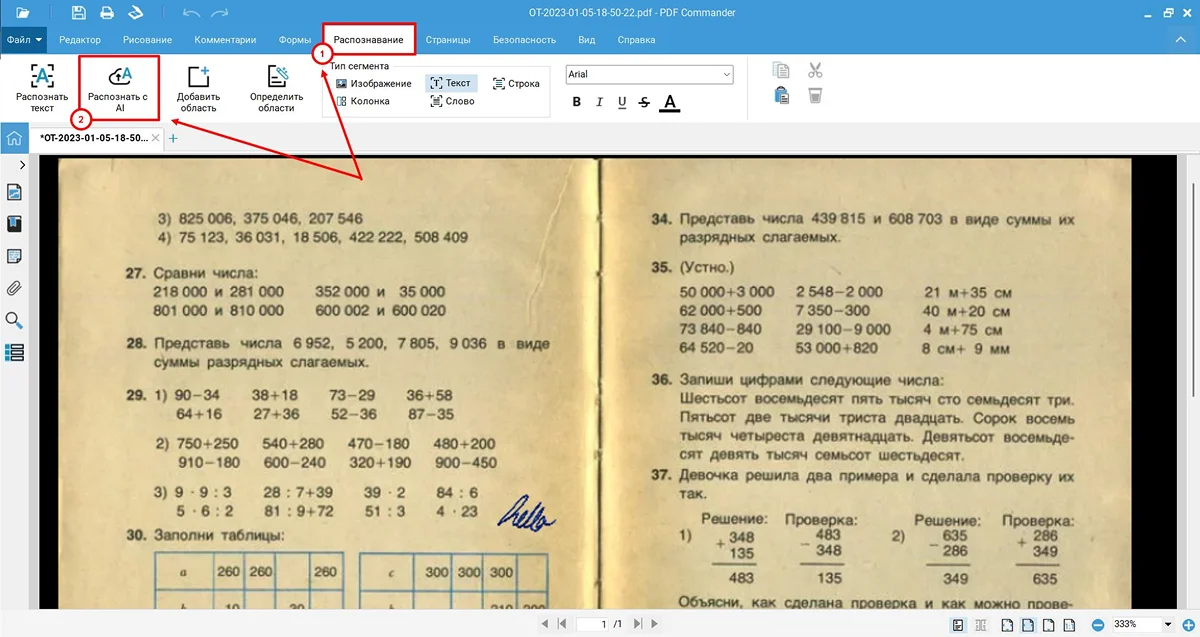
- 3. Поставьте галочку напротив нужного языка, кликните «Добавить невидимый слой текста», отметьте страницы. Запустите процесс считывания и дождитесь результата.
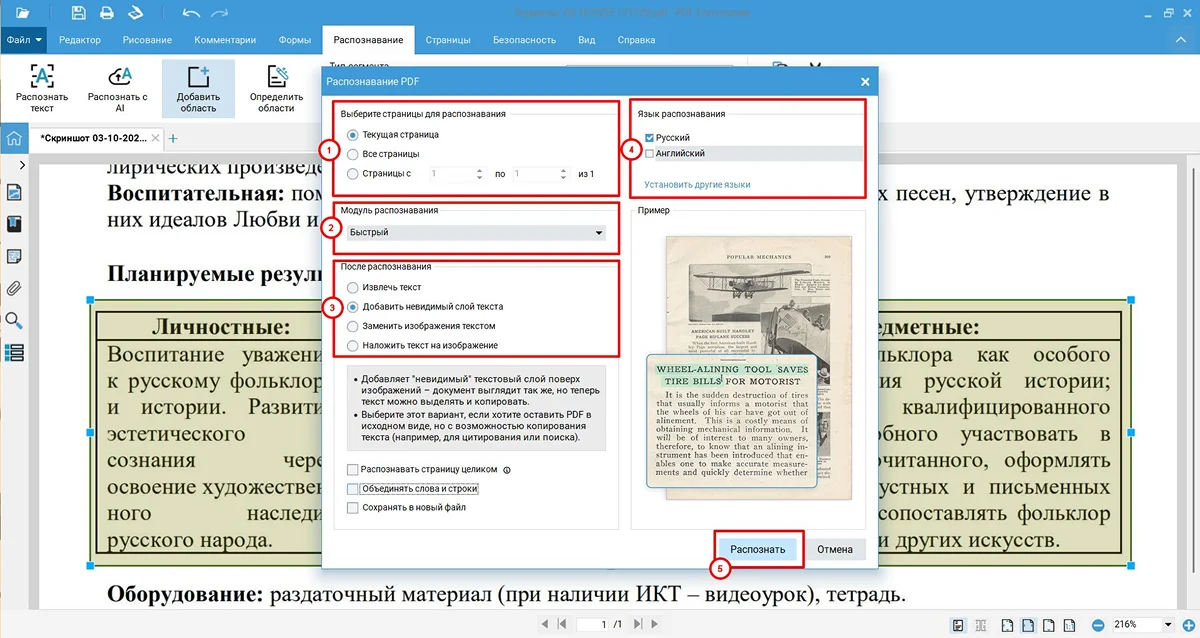
Как распознать данные в таблице
Иногда нам нужен не весь документ целиком, а только цифры или строки из таблицы, чтобы перенести их в журнал, сверить данные или использовать их в отчете.
Как определить текст с помощью OCR в таблице:
- 1. Загрузите исходный материал.
- 2. В разделе «Распознавание» кликните на «Колонку» и выделите таблицу. Так системе будет легче считать информацию.

- 3. Выберите режим «Текущая страница», интеллектуальный модуль, отметьте «Добавить невидимый слой текста» и определите язык. Запустите работу.
Какие еще программы и сервисы можно использовать
Распознать текст из ПДФ можно и в других программах. Поговорим, в каких ситуациях удобно обратиться к этим инструментам оптического распознавания.
| Инструмент | В каком случае удобно использовать |
| «Фрагмент и набросок» для Windows 11 | Когда вам не нужен целый файл, а лишь цитата или несколько предложений. Такой вариант не требует установки дополнительного ПО, но работает только с областью экрана, а не с цельным PDF-файлом. |
| Microsoft OneNote | Отличный вариант, если вы уже ведете свои заметки и материалы в этом приложении и необходимо быстро превратить документы в редактируемые файлы PDF. Точность считывания у этого инструмента для распознавания текста довольно высокая, однако OneNote работает только с изображениями внутри заметок. |
| Google Drive | Подойдет, если ваши данные уже хранятся в облаке и нужно получить из них редактируемый текст. Сервис доступен на любом устройстве. Тем не менее качество считывания сильно зависит от исходного разрешения файла. |
| Adobe Acrobat Pro | Это профессиональный стандарт, который стоит рассмотреть для сложных задач. Здесь есть редактирование отсканированных документов и перевод текста в PDF. В Adobe Acrobat Pro функция OCR позволяет легко считывать таблицы, сложные макеты и несколько языков. У ПО слишком высокая стоимость подписки, которая не оправдана для рядового пользователя. |
| NewOCR | Бесплатно поможет считать простой одностраничный файл и сделать текст в ПДФ редактируемым. Но на сайте много навязчивой рекламы, а его производительность зависит от загрузки сервера. |
| Text Fairy | Мобильное решение для тех, кому часто приходится определять текст в ПДФ прямо с телефона, фотографируя листы. Функционал ограничен распознаванием и копированием, редактировать PDF здесь не получится. |
В сравнении с этими программами PDF Commander остается универсальным решением. Он работает с целым ПДФ-файлом, считывает надписи с изображений, не зависит от скорости интернета и прост в использовании. Чтобы отредактировать файлы быстро, посмотрите наше обучающее видео по программе:

Заключение
PDF Commander хорошо показал себя в обработке разных типов файлов. Система смогла считать данные с фотографии, старого учебника, двуязычного текста и таблицы. Хотя в программе есть интеллектуальный модуль для работы со сложным материалом, лучше заранее подготовить изображения. Слова должны хорошо читаться и не сливаться с другими элементами: таблицами, рисунками, схемами. Это снижает вероятность ошибки и упрощает работу.
Ответы на часто задаваемые вопросы
OCR — это способ извлечь текст из отсканированных листов и превратить их в файл PDF с возможностью поиска. Система анализирует пиксели на фотографии, сопоставляет их с известными символами и создает текстовый слой на основе распознанных знаков.
Да, функция «AI-распознавание» в PDF Commander способна считывать почерк с точностью до 99%. Такие системы используют нейросети и хорошо справляются с четкими, аккуратными записями. Помните: если почерк неразборчивый, содержит пометки, сокращения или нестандартные символы, распознать текст с помощью OCR будет крайне проблематично.
Да, в PDF Commander сохраняется форматирование и структура исходного PDF-файла: абзацы, заголовки и списки. Это особенно удобно при работе с методическими материалами или официальными бланками.
Чтобы распознать текст в файле ПДФ, нужно добавить листы на сервер. Многие онлайн-сервисы временно хранят данные и используют их для улучшения своих алгоритмов. Если PDF-документ содержит конфиденциальную, личную или служебную информацию, лучше работать в десктопном ПО. Важно: большинство сервисов поддерживают только работу с PDF, если ваши данные в другом формате, их надо сначала конвертировать.
 Время чтения - 2 минуты
Время чтения - 2 минуты