
 Время чтения - 9 минут
Время чтения - 9 минут




Как эксперты PDF Commander проверяют софт для обзора?
- Изучают тарифы и политику разработчиков
- Тестируют программы на разных ПК
- Исследуют отзывы реальных пользователей
- Проверяют доступность и качество поддержки
- Исключают софт, который не обновляется

Работа с документами неразрывно связана с копированием содержимого. Однако иногда эта опция может быть недоступна. В статье узнаем, почему пользователи не могут копировать текст с PDF и что делать в этом случае.
Почему не копируется текст из PDF-документа
Возможны несколько причин, из-за которых часть страницы электронного документа не получится поместить в буфер обмена (то есть скопировать ее).
- Текстовое наполнение не распознано. Сразу после сканирования или при определенных настройках экспорта листы PDF-файла представляют собой изображения. Технически это почти то же самое, как если бы вы сфотографировали страницу.
- Доступ ограничен паролем. Защита может устанавливаться на просмотр PDF-документа, выделение, копирование его фрагментов и редактирование.
- Файл поврежден. Это происходит из-за случайных сбоев ПО, неисправности накопителей, и когда пересылка данных через электронную почту или мессенджеры неожиданно прерывается. Разработчики софта, который использовался для создания или обработки материала, могли нарушить требования стандарта PDF-файлов. В результате эти документы обозначаются как поврежденные, если попытаться открыть их в другой программе.
Как скопировать текст в PDF-файле, если он не копируется
Перейдем к практике и разберем, что делать, если не получается скопировать текст из PDF. Мы рассмотрим несколько типовых проблем и расскажем, как решить их при помощи приложения PDF Commander. Это простой в использовании, но при этом функциональный редактор. В программе есть конвертер документов Word и графических форматов, а также поддержка сканеров и другие полезные опции.
Снятие пароля и разрешение редактирования
Пароли могут скрывать содержимое PDF-файла от посторонних и запрещать его редактирование. Это делается для защиты авторских прав и конфиденциальных сведений. Разберем, как снять код, который вы знаете — чтобы не вводить его каждый раз.
- 1. При попытке открыть материал или выполнить другое действие, запрещенное изначальными настройками, появится окно для ввода пароля. Просто продолжить работу с файлом или изменить параметры приватности не получится. Для того чтобы получить доступ, сначала необходимо ввести комбинацию.
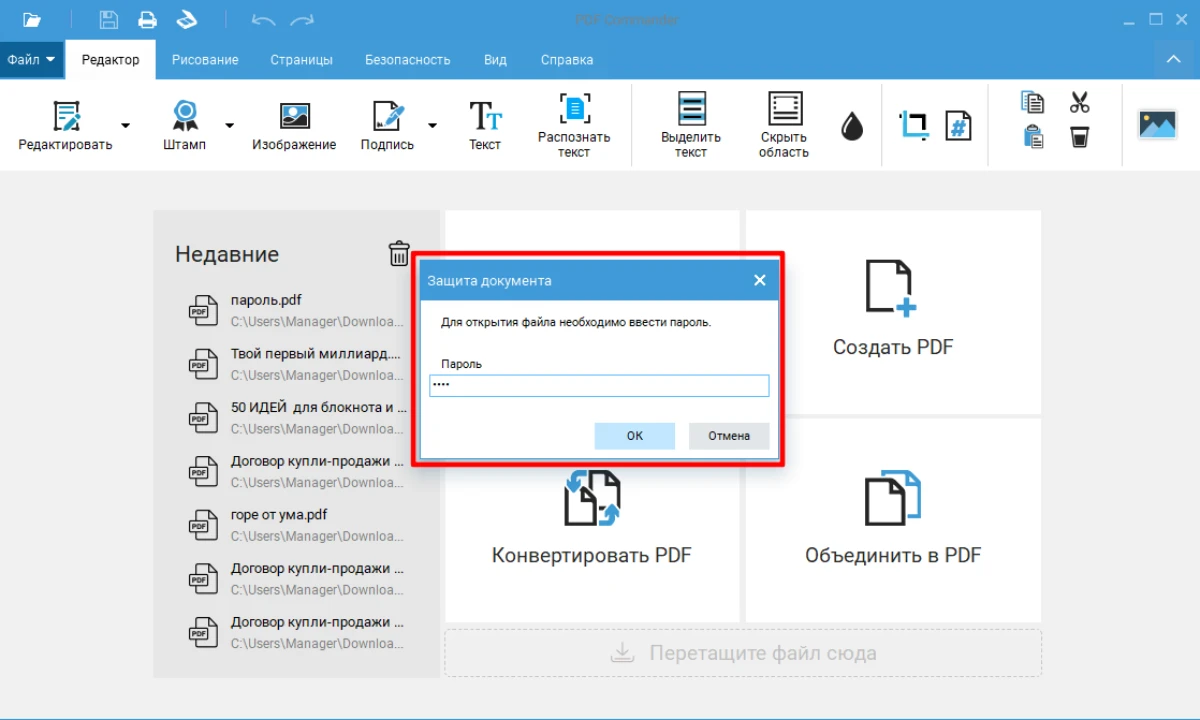
- 2. Перейдите во вкладку «Безопасность» и кликните «Задать пароль».
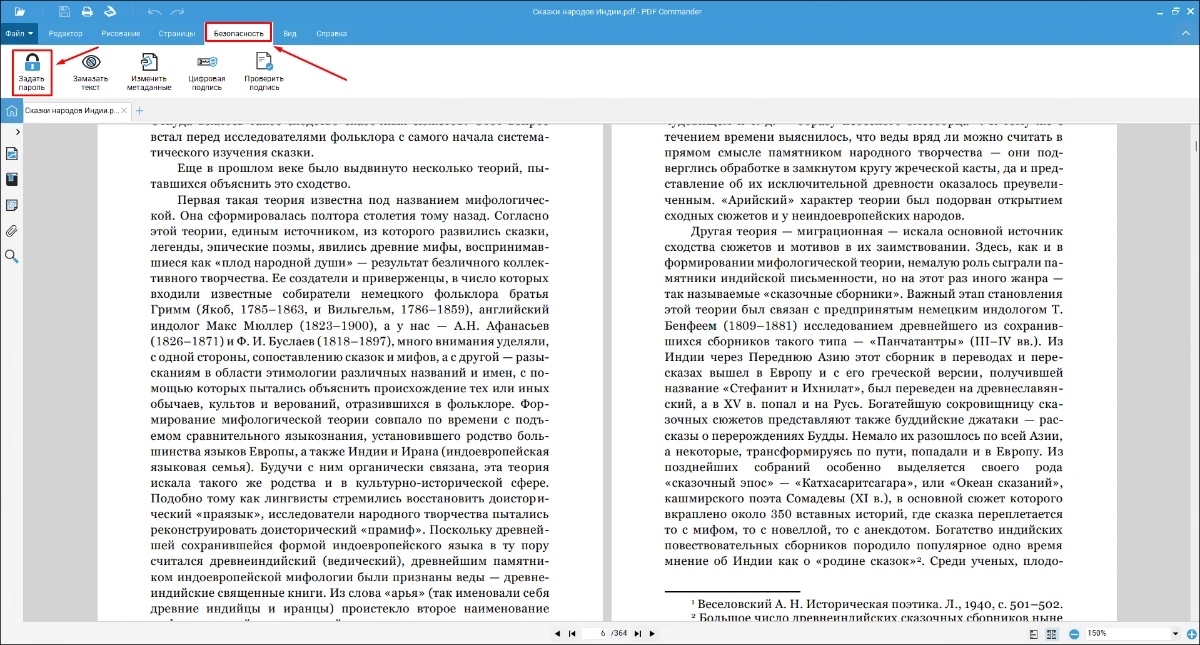
- 3. Нажмите «Снять защиту». После этого необходимо сохранить измененный PDF-файл.
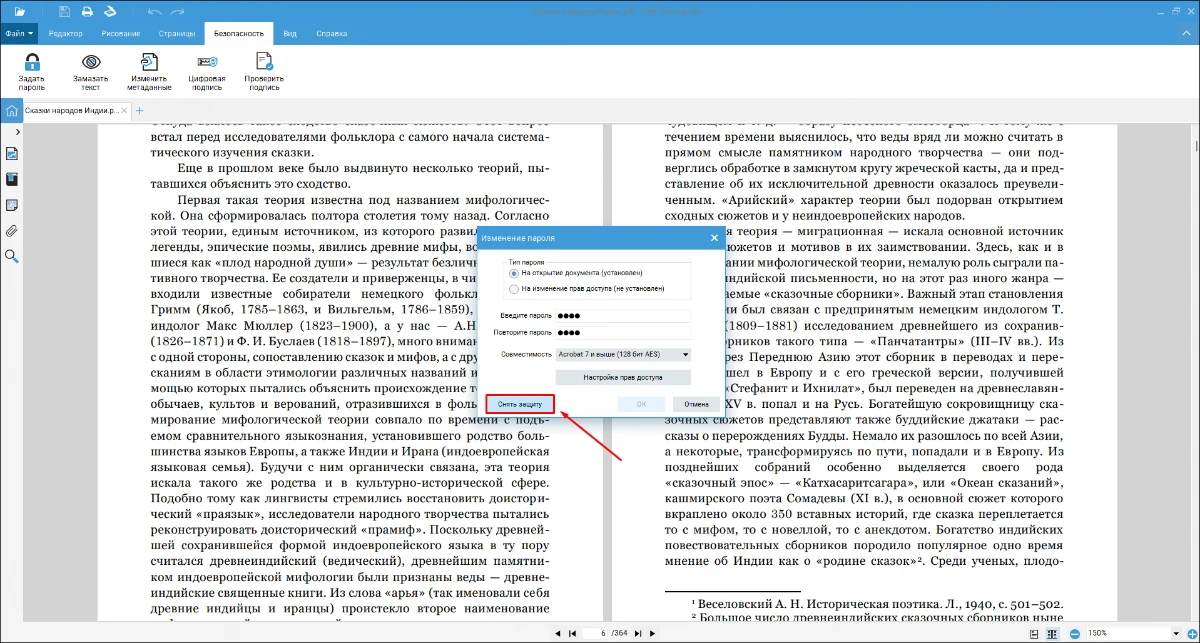
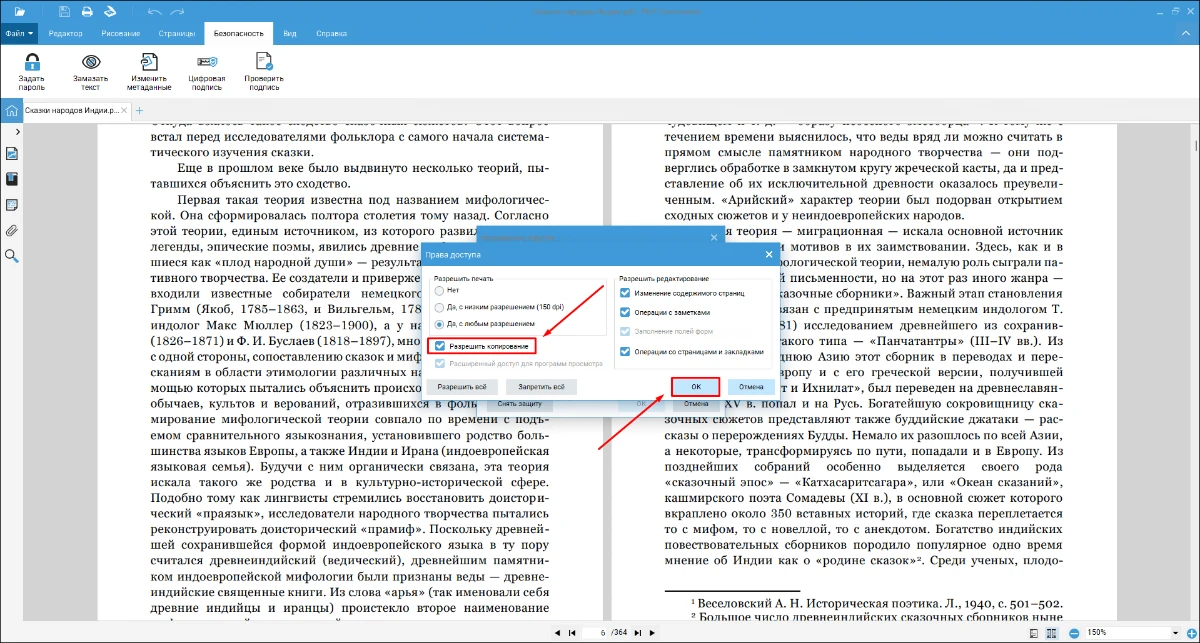
- 4. Можно сохранить пароль, но поменять его тип. Детальные параметры приватности открывает кнопка «Настройка прав доступа».
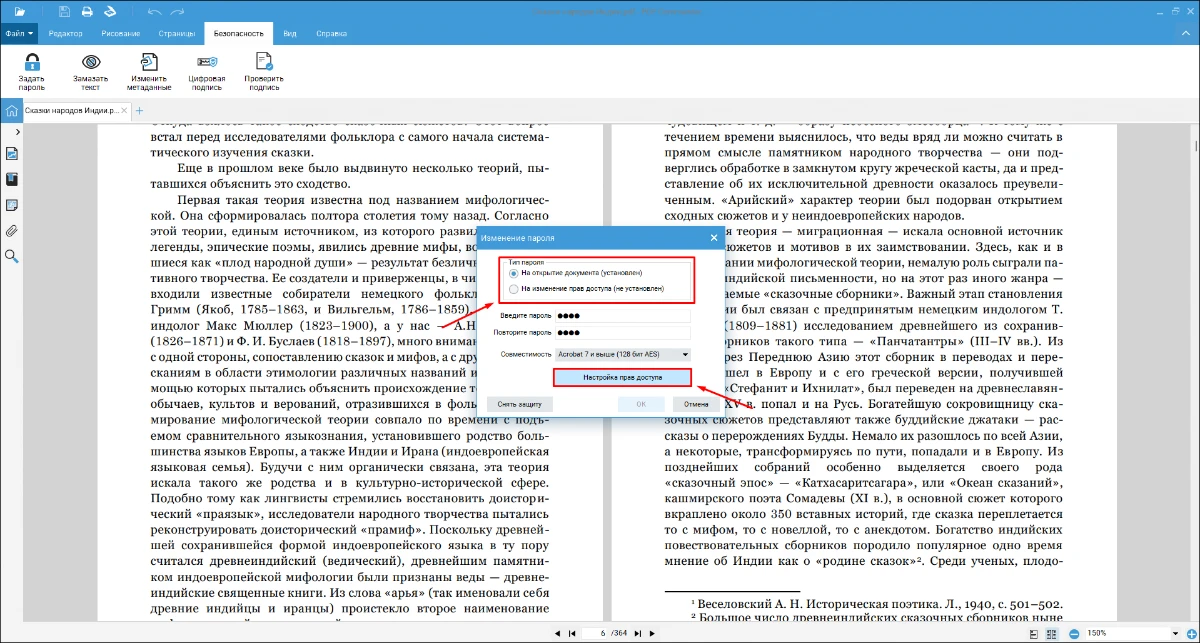
- 5. Убедитесь, что опция «Разрешить копирование» активирована, и сохраните измененные настройки нажав кнопку «ОК».
Распознавание текста (OCR)
Инструмент оптического распознавания символов (OCR) анализирует страницы и сопоставляет визуальные образы с контурами соответствующих букв, цифр и других знаков. После обработки становятся доступными опции поиска слов, их выделения, копирования и редактирования.
- 1. Запустите PDF Commander, после чего импортируйте в него документ. Также можно перенести файл в окно программы.
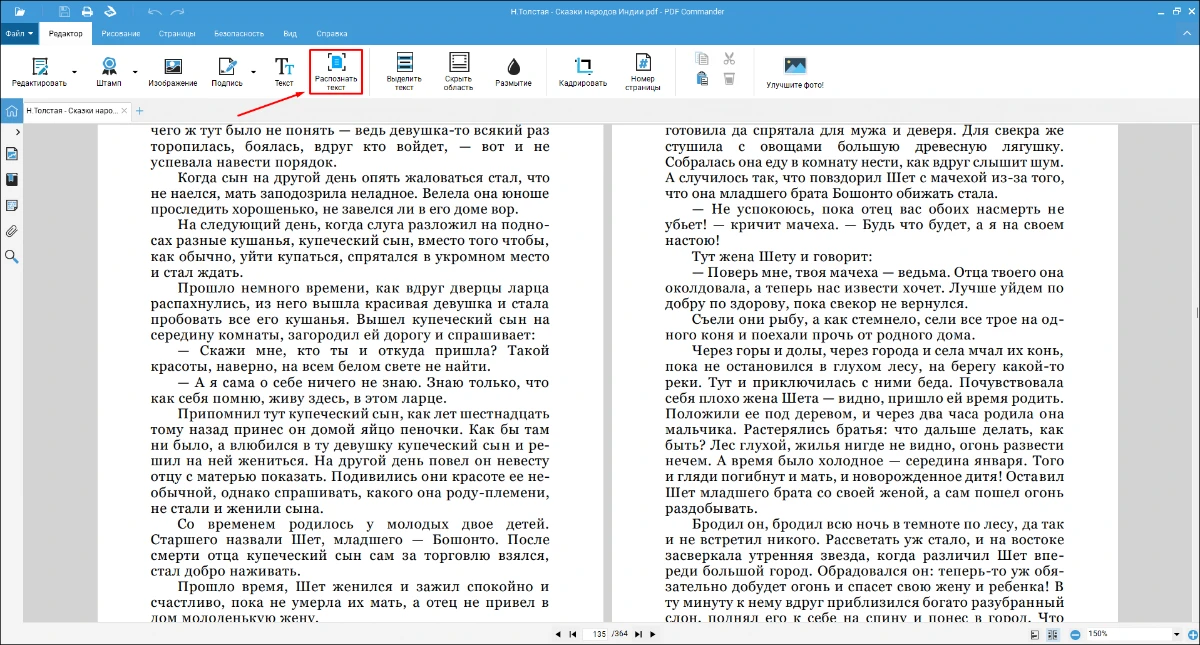
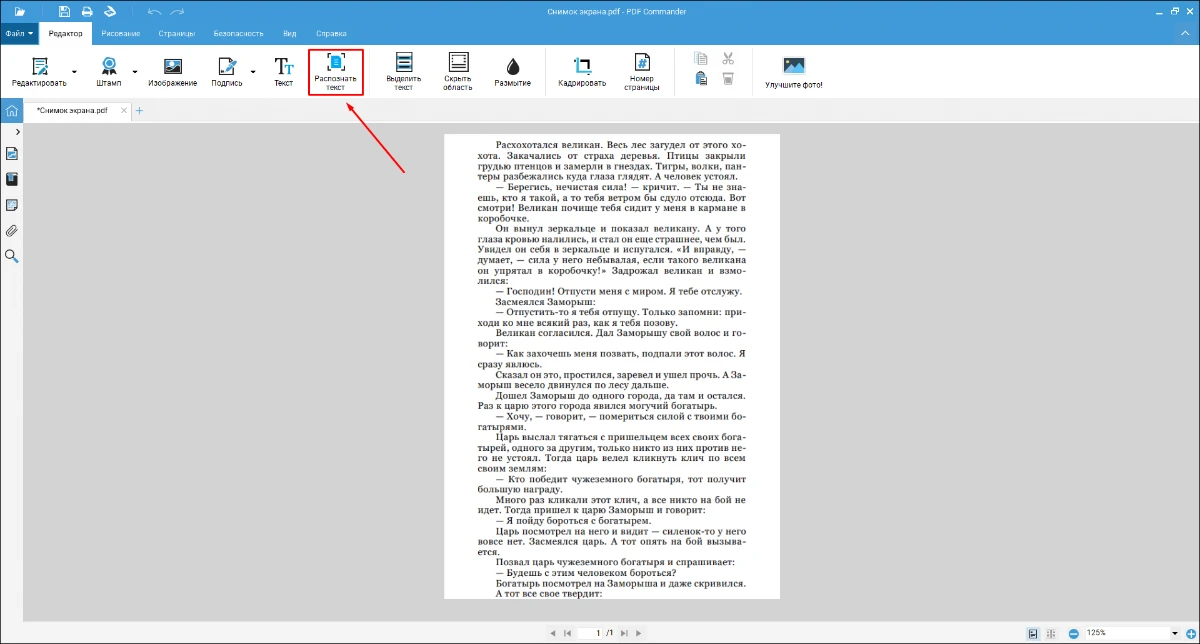
- 2. Перейдите в редактор и выберите распознавание.
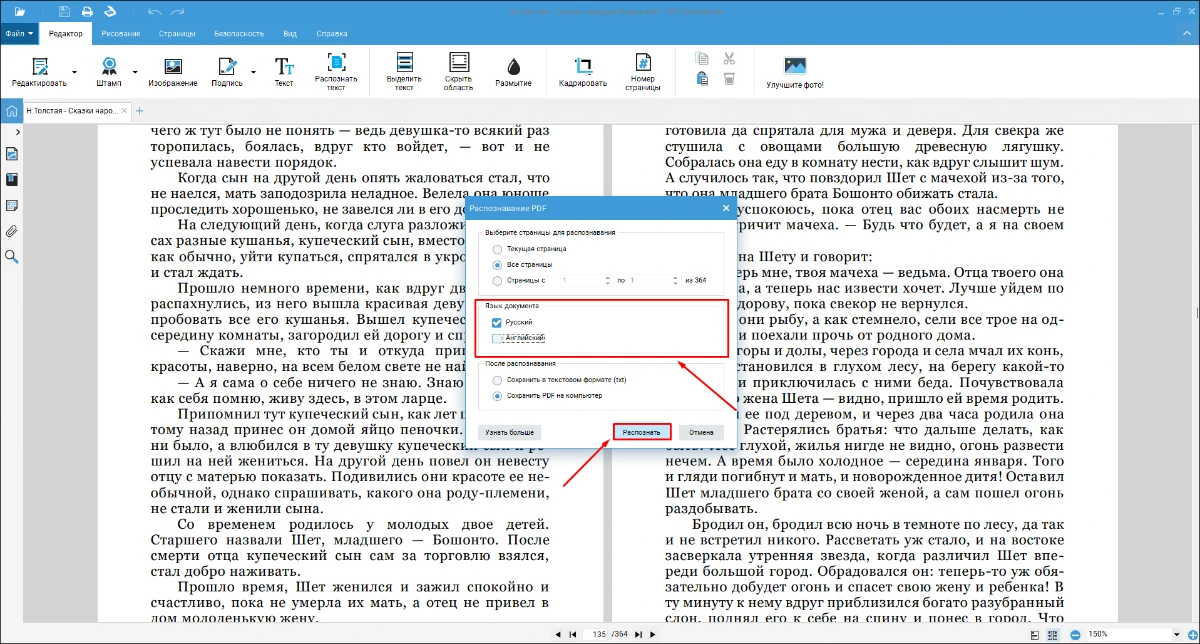
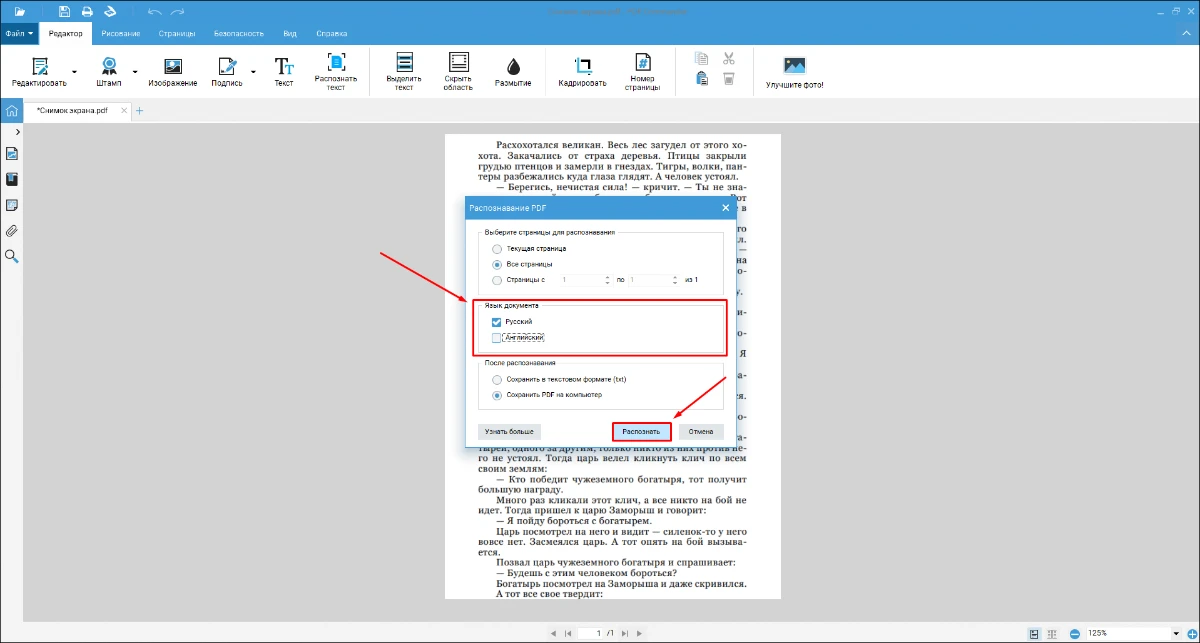
- 3. Опция OCR доступна для русского и английского языков. Выберите нужный и кликните «Распознать», чтобы начать обработку.
Функция OCR придет на помощь и в тех случаях, когда содержимое файлов защищено от копирования, но вы забыли пароль. Для удобства можно открыть несколько окон программы, чтобы быстро переносить текст из одного файла в другой.

- 1. Откройте PDF-документ в любом просмотрщике, например в вашем браузере.
- 2. Сделайте скриншот страницы. В Windows 10 и 11 для этого подойдет встроенный софт «Ножницы». Нажмите сочетание клавиш Shift + Win + S и выделите фрагмент экрана.
- 3. Щелкните на всплывающее уведомление, которое появится в нижнем правом углу экрана.
- 4. Кликните по значку дискеты и сохраните результат как PNG- или JPEG-файл.

- 5. Перетащите файл со снимком экрана в PDF Commander. После этого программа автоматически создаст новый PDF-документ.
- 6. Нажмите «Распознать текст».
- 7. Укажите нужный язык и запустите обработку.
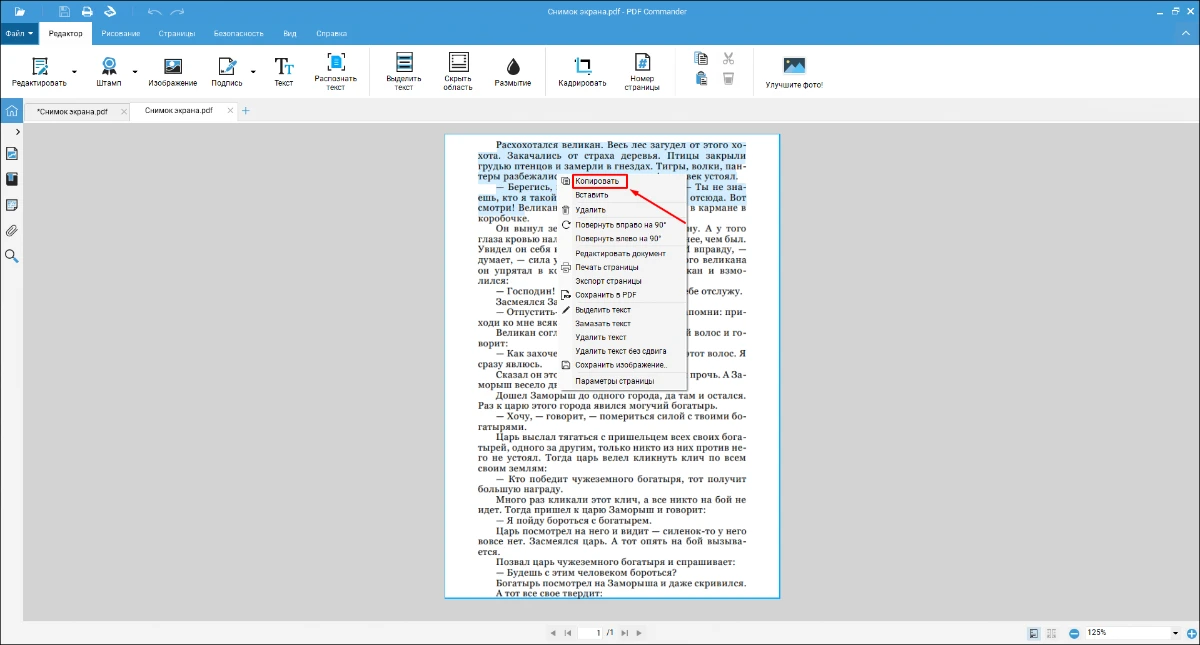
- 8. Когда обработка завершится, копирование, выделение и поиск станут доступны.

Исправление повреждения
Можно попробовать повторно сохранить поврежденный PDF-документ или запустить преобразование форматов, а затем воспользоваться методом с OCR, о котором рассказали выше.
- 1. Откройте PDF-файл в редакторе.
- 2. Сохраните материал через опции в меню «Файл».
- 3. Запустите PDF Commander и запустите конвертацию.
- 4. Выберите исходный материал.
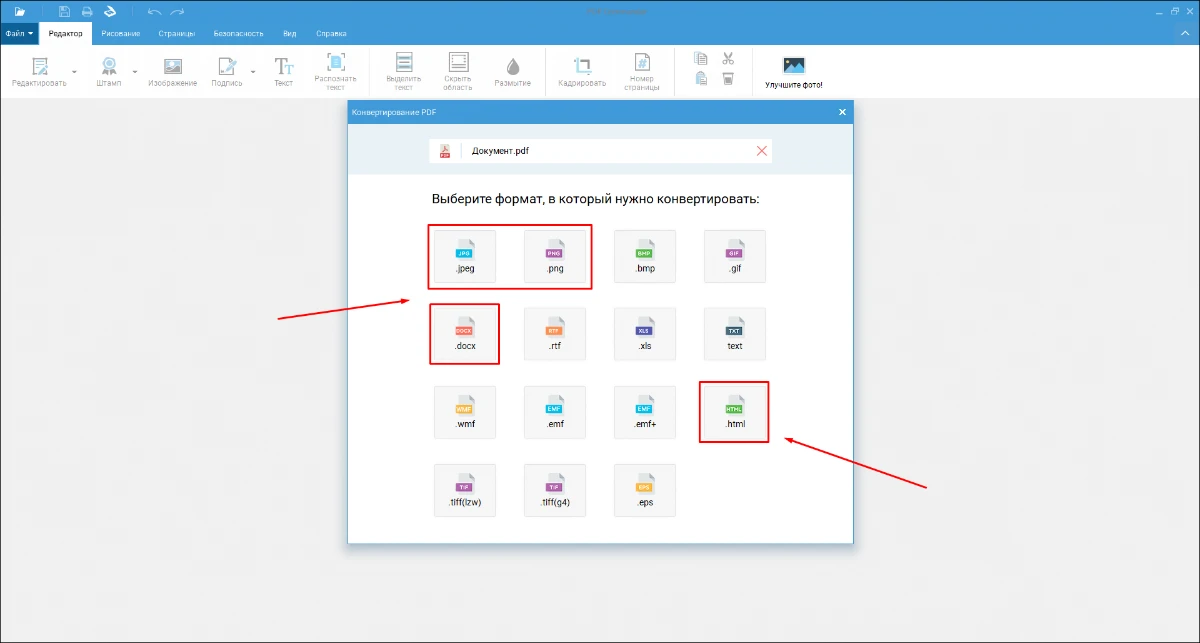
- 5. Укажите для конвертера тип конечного файла. Если поврежденный материал предположительно был распознан, можно выбрать формат DOC (DOCX) или HTML. В противном случае вы можете преобразовать документ в изображение. Например, в формат JPEG или PNG. Затем примените OCR.
В случае, если предложенный метод не поможет, можно попробовать восстановить PDF при помощи специальных приложений.
Работа со сканами
Проблемы с копированием часто возникают из-за неправильно выставленных настроек при оцифровке бумажных материалов. Разберем процесс, чтобы вы получили полноценный PDF-документ, а не просто сохранили картинку.
- 1. Откройте программу и кликните по значку сканера.
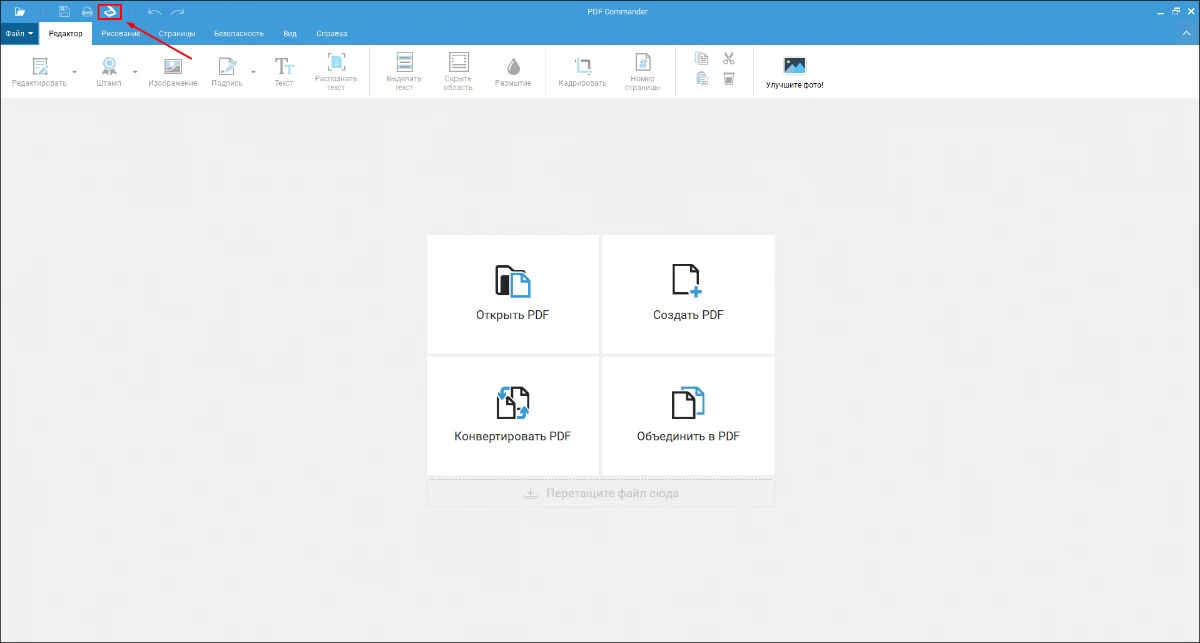
- 2. Задайте разрешение и режим цвета, а затем нажмите «Сканировать».
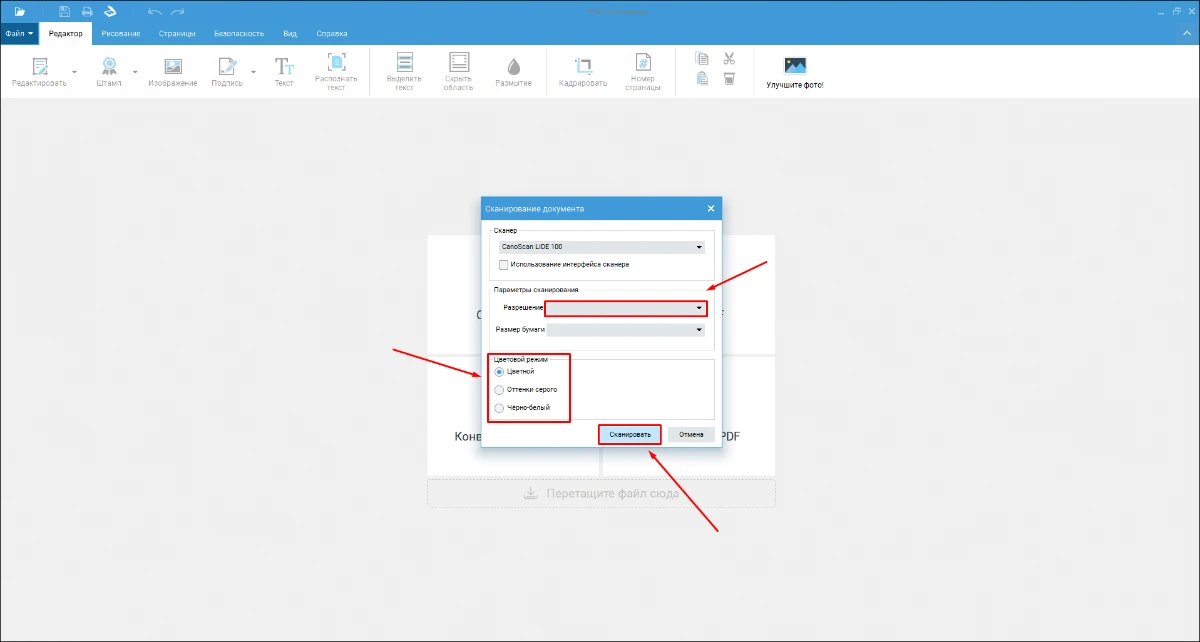
- 3. При необходимости кадрируйте оцифрованную страницу.
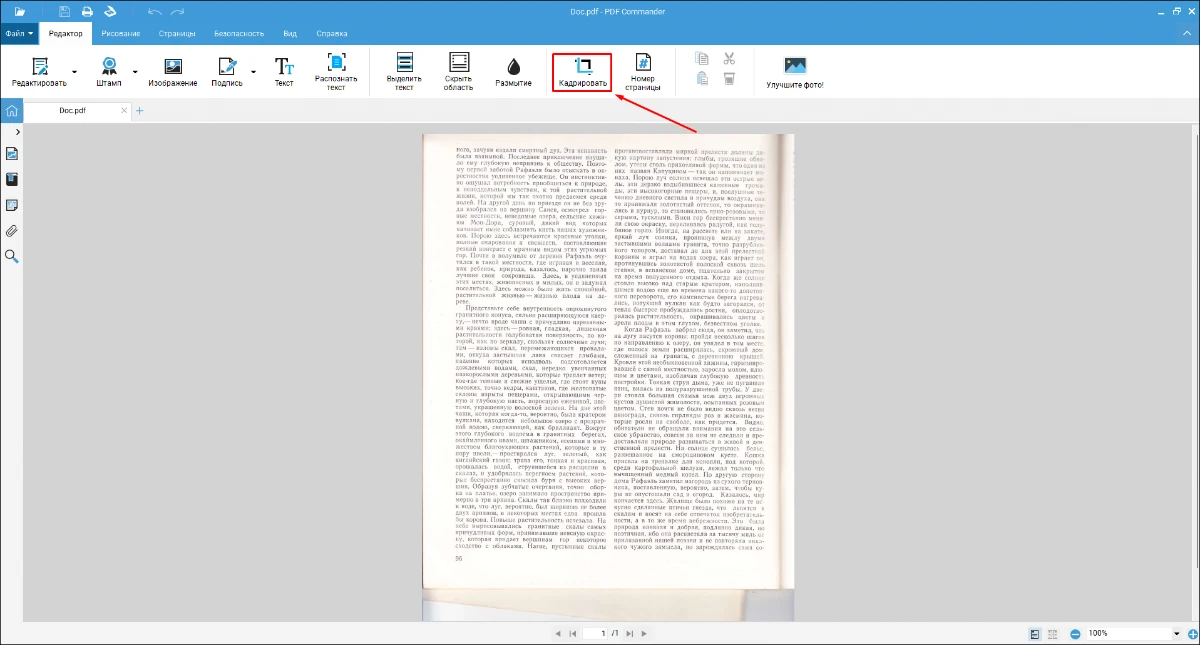
- 4. Запустите распознавание символов.
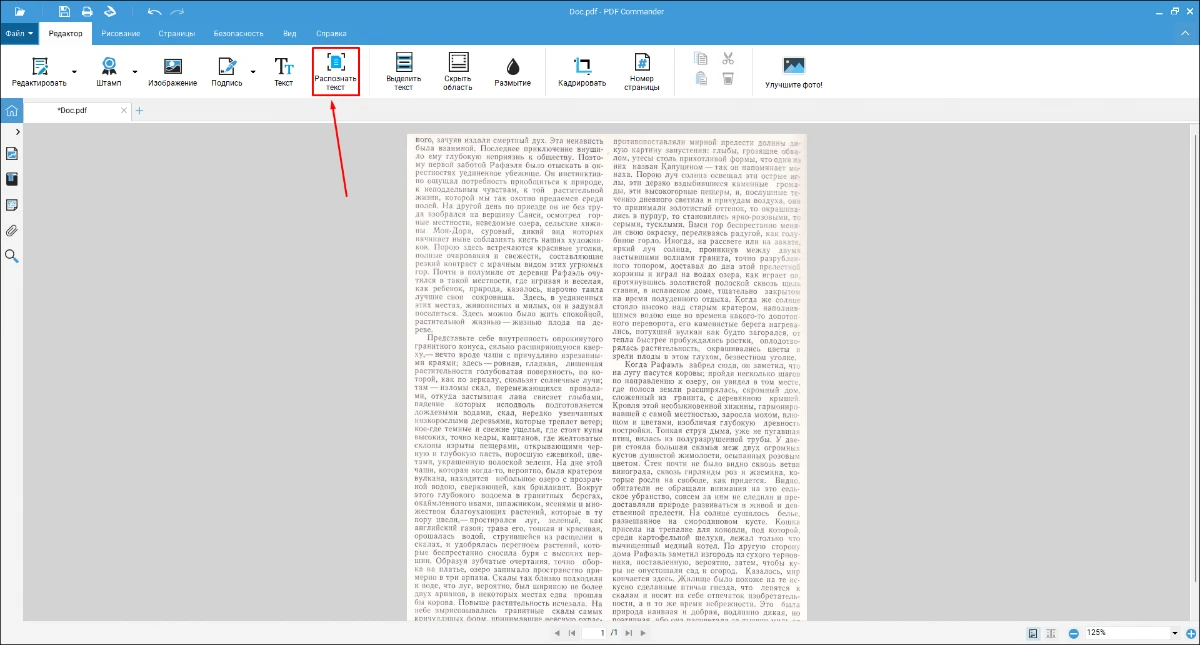
- 5. Укажите подходящий язык и нажмите «Распознать».

Как можно использовать инструменты Google
Если ПДФ не дает копировать текст из-за пароля, проблему можно решить при помощи браузера Chrome и функционала облачного сервиса Google Диск.
Открытие в Google Chrome
- 1. Вставьте исходный PDF-файл в браузер.
- 2. Нажмите значок принтера.
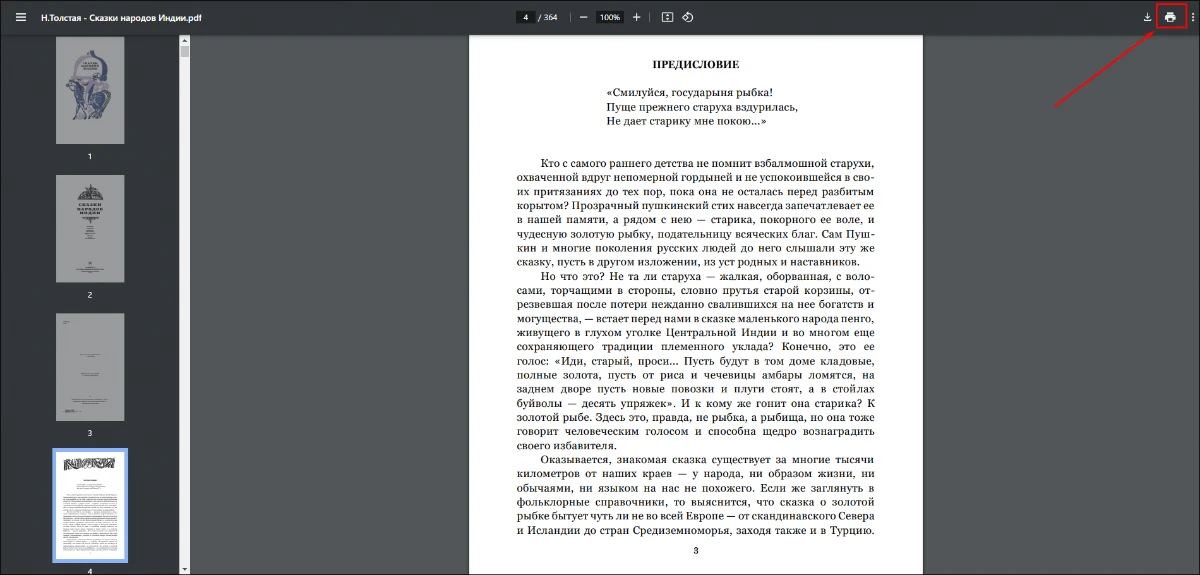
- 3. В списке «Принтер» выберите «Microsoft Print to PDF» или «Сохранить как PDF».
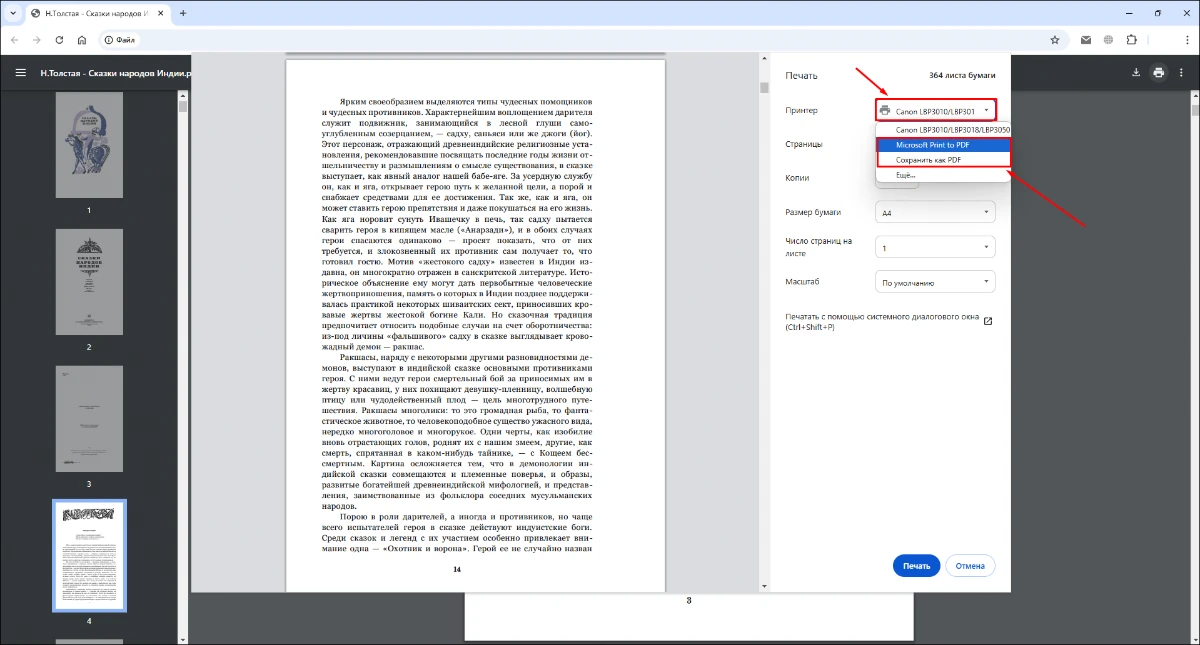
- 4. Укажите, какие страницы нужно пересохранить, и нажмите «Печать». Далее нужно задать расположение и название нового PDF-файла.
- 5. В процессе печати через виртуальный принтер пароль на копирование вводить не нужно, а в новом документе его не будет.
Открытие в Google Docs через Диск
- 1. Откройте страртовую страницу Google и перейдите в Диск. Если у вас нет учетной записи, сначала придется ее зарегистрировать.
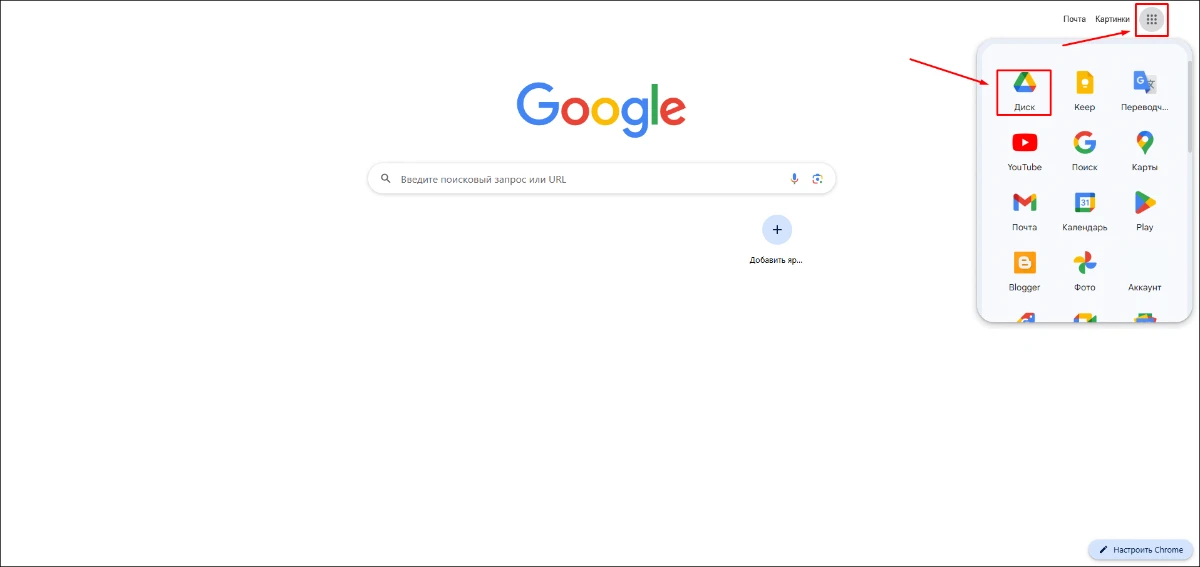
- 2. Загрузите PDF-документ в облако, перетащив файл во вкладку с открытым Диском.
- 3. Откройте загруженный материал и кликните «Открыть в приложении “Google Документы”».
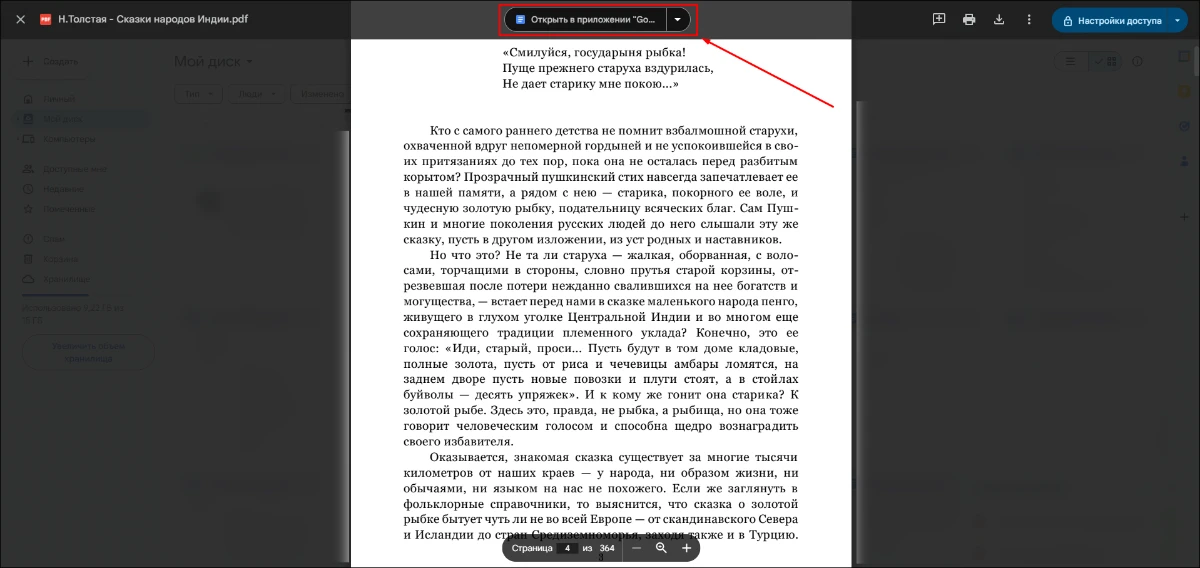
- 4. Содержание импортируется в текстовый редактор. Однако сервис пока не умеет извлекать изображения, поэтому иллюстрации будут утрачены.
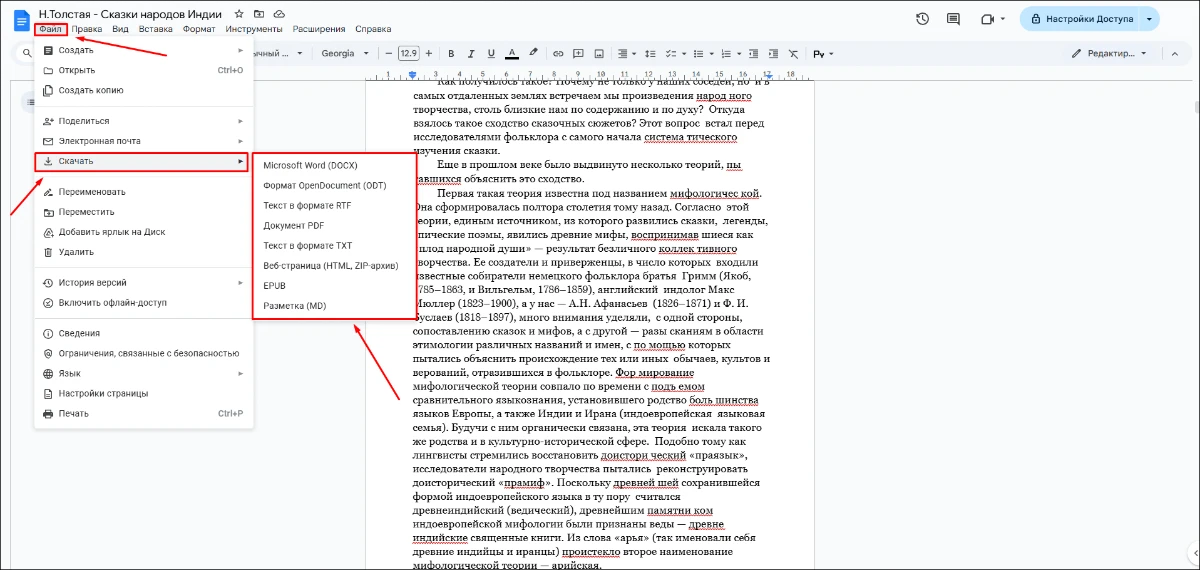
- 5. Вы можете оставить результат в облаке или скачать на компьютер через «Файл».
Резюмируем
Вы узнали, как скопировать текст с ПДФ-файла, если он никак не копируется и не выделяется.

Часто задаваемые вопросы
Попробуйте выделить одно или несколько слов. Если не получится, значит, страницы документа представляют собой изображения.
Чтобы уменьшить размер файла, или из-за неправильной настройки иногда шрифты не встраиваются в PDF-документ. При этом может нарушаться стандартная символьная кодировка. Буква в документе имеет обозначение, которое обычно соответствует другому знаку. В итоге содержимое буфера обмена состоит из нечитаемого набора символов.
Это может быть связано с тем, что выставлена другая кодировка. Системные обозначения кириллических или латинских символов в документе не соответствуют стандартным раскладкам. Проблема может возникнуть при сжатии файла специальной функцией в приложении для работы с ПДФ. Либо разработчики этого ПО не полностью придерживаются требований формата.
 Время чтения - 7 минут
Время чтения - 7 минут